
使用 TypeScript 和 Jupyter 构建自定义 RAG AI 代理

这是关于使用 Deno 构建 LLM 系列的第 2 部分。 在此处查看第一部分。
在我的上一篇博客文章中,我演示了如何通过 Deno 与本地 LLM 进行交互。在本文中,我想更进一步,构建一个 AI 检索增强生成 (RAG) 代理。RAG 代理是结合了基于检索的方法和生成模型的人工智能系统,旨在为查询提供更准确、更具上下文相关性的响应。
正如我在之前的文章中提到的,我现在的工作是就技术影响向投资者、董事会和高级管理人员提供建议。具体来说,我们作为公司投资过程的一部分,做了大量的技术尽职调查。我们有大量高度机密的文件,必须在很短的时间内阅读和分析。研究人工智能如何成为一种辅助工具,并以可证明安全的方式实现,促使我进行了 RAG 代理实验。
在本篇博客文章中,我们将进行以下操作:
- 检索并准备多篇博客文章,供我们的 AI 代理使用。
- 创建一个具有多种工具的 AI 代理
- 一个用于查询数据库中博客文章的工具。
- 一个用于评估文档是否与查询相关的工具。
- 能够根据需要重写和改进查询。
- 最后,我们根据收集到的信息对查询生成响应。
开始
这篇博客文章将基于上一篇博客文章,并假设您已在本地安装了最新版本的 Deno 和 Ollama。
在上一篇文章中,我们使用了 Ollama 的 80 亿参数的 Deepseek R1 (deepseek-r1:8b)。虽然我们仍将使用 Deepseek R1 生成最终输出,但我们将使用另外两个专为我们将要执行的任务量身定制的模型:
- Mixedbread 的嵌入模型 (
mxbai-embed-large)。嵌入模型用于将文本转换为便于 AI 系统搜索的形式。 - Meta 的 Llama 3.2 30 亿参数模型 (
llama3.2:3b)。该模型支持工具,允许大型语言模型调用执行额外操作的工具/函数。
⚠️ Ollama 下应该有相当多的模型支持工具。然而,在那些适合在本地机器上运行且大小合理的模型中,只有 Llama 3.2 我能让它正常工作。
您需要确保本地已安装这些模型
ollama pull mxbai-embed-large
ollama pull llama3.2:3b在开始之前,让我们告知 Deno 如何最好地处理我们将动态导入的 npm 依赖项。在项目目录中,确保您有如下所示的最小 deno.json 文件
{
"nodeModulesDir": "auto"
}将 "nodeModulesDir" 设置为 "auto" 将确保在 Jupyter Notebook 下模块解析正常工作,尽管您也可能跳过此步骤而不会遇到任何问题。
请注意,本文中的某些示例专门设计用于 Deno Jupyter notebook,例如当我们显示将要构建的代理的结构时。如果您想创建一个新的 Jupyter notebook,请参考之前的博客文章。
收集我们的文档
第一步是为我们的代理收集和处理文档。我们将
- 抓取 Deno 博客上的几篇文章,
- 处理它们并将其存储在内存向量存储中,以及
- 创建一个允许访问存储的检索器
我们将使用 Cheerio 来抓取和解析 HTML,然后使用递归文本分割器将我们的博客文章分割成更小的文档,以便代理更容易管理。最后,我们将文档转换为可以被代理搜索和管理的形式。
⚠️ 您可以使用其他向量存储来持久化数据。Chroma 是在本地运行的理想选择。它设置 Docker 容器非常容易,并且在 LangChain 中也得到了很好的支持。
import { OllamaEmbeddings } from "npm:@langchain/ollama";
const embeddings = new OllamaEmbeddings({
model: "mxbai-embed-large",
});
import "npm:cheerio";
import { CheerioWebBaseLoader } from "npm:@langchain/community/document_loaders/web/cheerio";
const urls = [
"https://deno.org.cn/blog/not-using-npm-specifiers-doing-it-wrong",
"https://deno.org.cn/blog/v2.1",
"https://deno.org.cn/blog/build-database-app-drizzle",
];
const docs = await Promise.all(
urls.map((url) => new CheerioWebBaseLoader(url).load()),
);
const docsList = docs.flat();
import { RecursiveCharacterTextSplitter } from "npm:@langchain/textsplitters";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const allSplits = await splitter.splitDocuments(docsList);
console.log(`Split blog posts into ${allSplits.length} sub-documents.`);
import { MemoryVectorStore } from "npm:langchain/vectorstores/memory";
const vectorStore = await MemoryVectorStore.fromDocuments(
allSplits,
embeddings,
);
const retriever = vectorStore.asRetriever();Split blog posts into 170 sub-documents.我们已成功检索、解析、拆分并存储了三篇 Deno 博客文章,供我们的 AI 代理使用。
图与状态
在检索增强生成(RAG)代理的上下文中,“图”通常指信息的结构化表示,它能使代理在决策或生成过程中高效地检索、推理和管理上下文。
图指的是信息的结构化表示,它使代理能够高效地检索、推理和管理上下文。它将处理我们的查询并需要一个简单的状态。现在就创建它,因为我们可以使用它的 type 来帮助构建我们系统的其他部分。
import { Annotation } from "npm:@langchain/langgraph";
import { BaseMessage } from "npm:@langchain/core/messages";
const GraphState = Annotation.Root({
messages: Annotation<BaseMessage[]>({
reducer: (x, y) => x.concat(y),
default: () => [],
}),
});检索器工具
我们有我们的检索器(一个搜索和访问我们文档的接口),但我们需要将其转换为一个将提供给我们的代理的工具
import { createRetrieverTool } from "npm:langchain/tools/retriever";
import { ToolNode } from "npm:@langchain/langgraph/prebuilt";
const tool = createRetrieverTool(
retriever,
{
name: "retrieve_blog_posts",
description:
"Search and return information about Deno from various blog posts.",
},
);
const tools = [tool];
const toolNode = new ToolNode<typeof GraphState.State>(tools);我们代理工作流的组件
接下来,我们将创建几个节点(函数)来执行工作流的各个部分
shouldRetrieve()- 确定我们是否需要从数据库中检索文档。gradeDocuments()- 对文档进行评分以确定其相关性。checkRelevance()- 协调文档的评分。agent()- 我们的核心代理,它决定下一步行动。rewrite()- 重写我们的查询以尝试找到相关文档。generate()- 根据查询和找到的文档生成输出。
这些节点中的每一个都接收图的 state 并返回一条消息。
import { ChatPromptTemplate } from "npm:@langchain/core/prompts";
import { ChatOllama } from "npm:@langchain/ollama";
import { isAIMessage, isToolMessage } from "npm:@langchain/core/messages";
import { END } from "npm:@langchain/langgraph";
import { z } from "npm:zod";
function shouldRetrieve(state: typeof GraphState.State): string {
console.log("---DECIDE TO RETRIEVE---");
const { messages } = state;
const lastMessage = messages[messages.length - 1];
if (isAIMessage(lastMessage) && lastMessage.tool_calls?.length) {
console.log("---DECISION: RETRIEVE---");
return "retrieve";
}
return END;
}
async function gradeDocuments(
state: typeof GraphState.State,
): Promise<Partial<typeof GraphState.State>> {
console.log("---GET RELEVANCE---");
const tool = {
name: "give_relevance_score",
description: "Give a relevance score to the retrieved documents.",
schema: z.object({
binaryScore: z.string().describe("Relevance score 'yes' or 'no'"),
}),
};
const prompt = ChatPromptTemplate.fromTemplate(
`You are a grader assessing relevance of retrieved docs to a user question.
Here are the retrieved docs:
-------
{context}
-------
Here is the user question: {question}
If the content of the docs are relevant to the users question, score them as relevant.
Give a binary score 'yes' or 'no' score to indicate whether the docs are relevant to the question.
Yes: The docs are relevant to the question.
No: The docs are not relevant to the question.`,
);
const model = new ChatOllama({
model: "llama3.2:3b",
temperature: 0,
}).bindTools([tool]);
const { messages } = state;
const firstMessage = messages[0];
const lastMessage = messages[messages.length - 1];
const chain = prompt.pipe(model);
const score = await chain.invoke({
question: firstMessage.content as string,
context: lastMessage.content as string,
});
return {
messages: [score],
};
}
function checkRelevance(state: typeof GraphState.State): "yes" | "no" {
console.log("---CHECK RELEVANCE---");
const { messages } = state;
const lastMessage = messages[messages.length - 1];
if (!isAIMessage(lastMessage)) {
throw new Error(
"The 'checkRelevance' node requires the most recent message to be an AI message.",
);
}
const { tool_calls: toolCalls } = lastMessage;
if (!toolCalls || !toolCalls.length) {
throw new Error(
"The 'checkRelevance' node requires the most recent message to contain tool calls.",
);
}
if (toolCalls[0].args.binaryScore === "yes") {
console.log("---DECISION: DOCS RELEVANT---");
return "yes";
}
console.log("---DECISION: DOCS NOT RELEVANT---");
return "no";
}
async function agent(
state: typeof GraphState.State,
): Promise<Partial<typeof GraphState.State>> {
console.log("---CALL AGENT---");
const { messages } = state;
const filteredMessages = messages.filter((message) => {
if (isAIMessage(message) && message.tool_calls?.length) {
return message.tool_calls[0].name !== "give_relevance_score";
}
return true;
});
const model = new ChatOllama({
model: "llama3.2:3b",
temperature: 0,
streaming: true,
}).bindTools(tools);
const response = await model.invoke(filteredMessages);
return {
messages: [response],
};
}
async function rewrite(
state: typeof GraphState.State,
): Promise<Partial<typeof GraphState.State>> {
console.log("---TRANSFORM QUERY---");
const { messages } = state;
const question = messages[0].content as string;
const prompt = ChatPromptTemplate.fromTemplate(
`Look at the input and try to reason about the underlying semantic intent / meaning.
Here is the initial question:
-------
{question}
-------
Formulate an improved question:`,
);
// Grader
const model = new ChatOllama({
model: "deepseek-r1:8b",
temperature: 0,
streaming: true,
});
const response = await prompt.pipe(model).invoke({ question });
return {
messages: [response],
};
}
async function generate(
state: typeof GraphState.State,
): Promise<Partial<typeof GraphState.State>> {
console.log("---GENERATE---");
const { messages } = state;
const question = messages[0].content as string;
// Extract the most recent ToolMessage
const lastToolMessage = messages.slice().reverse().find((msg) =>
isToolMessage(msg)
);
if (!lastToolMessage) {
throw new Error("No tool message found in the conversation history");
}
const context = lastToolMessage.content as string;
const prompt = ChatPromptTemplate.fromTemplate(
`You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Here is the initial question:
-------
{question}
-------
Here is the context that you should use to answer the question:
-------
{context}
-------
Answer:`,
);
const llm = new ChatOllama({
model: "deepseek-r1:8b",
temperature: 0,
streaming: true,
});
const ragChain = prompt.pipe(llm);
const response = await ragChain.invoke({
context,
question,
});
return {
messages: [response],
};
}生成工作流
现在我们需要向工作流添加节点
import { StateGraph } from "npm:@langchain/langgraph";
const workflow = new StateGraph(GraphState)
.addNode("agent", agent)
.addNode("retrieve", toolNode)
.addNode("gradeDocuments", gradeDocuments)
.addNode("rewrite", rewrite)
.addNode("generate", generate);然后我们需要提供关于节点之间如何相互关联的特定指令,并编译我们的工作流
import { START } from "npm:@langchain/langgraph";
// Call agent node to decide to retrieve or not
workflow.addEdge(START, "agent");
// Decide whether to retrieve
workflow.addConditionalEdges(
"agent",
// Assess agent decision
shouldRetrieve,
);
workflow.addEdge("retrieve", "gradeDocuments");
// Edges taken after the `action` node is called.
workflow.addConditionalEdges(
"gradeDocuments",
// Assess agent decision
checkRelevance,
{
// Call tool node
yes: "generate",
no: "rewrite", // placeholder
},
);
workflow.addEdge("generate", END);
workflow.addEdge("rewrite", "agent");
// Compile
const app = workflow.compile();
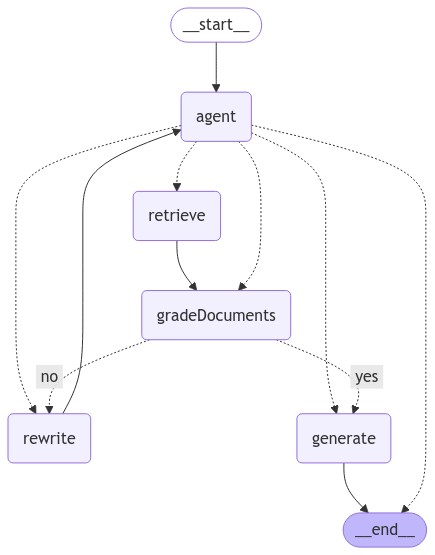
// If running in a Jupyter notebook, display the graph visually
Deno.jupyter.image(
await (await (await app.getGraphAsync()).drawMermaidPng()).bytes(),
);生成的 Deno.jupyter.image 图表如下所示
向代理提问
最后,我们可以使用我们的代理了!让我们向代理提一个问题(“Deno 2.1 有哪些新特性?”),看看响应是什么。
import { HumanMessage } from "npm:@langchain/core/messages";
const inputs = {
messages: [
new HumanMessage("What are some new features of Deno 2.1?"),
],
};
let finalState;
for await (const output of await app.stream(inputs)) {
for (const [key, value] of Object.entries(output)) {
console.log(`${key} -->`);
finalState = value;
}
}
const lastMessage = finalState.messages[finalState.messages.length - 1];
const content = lastMessage.content
.replace("<think>", "<details><summary>Thinking...</summary>")
.replace("</think>", "</details>");
Deno.jupyter.md`Generated output from agent:
${content}`;代理生成的输出
思考中……好的,我需要根据提供的上下文找出 Deno 2.1 的新功能。让我先仔细阅读上下文。
首先提到的是 Deno 2.1 支持 Wasm 导入。这是一个重要功能,因为它允许与 WebAssembly 更好地集成,可以提高性能和功能。
接下来,提到了在使用
deno compile编译期间嵌入资产文件。这可能意味着用户可以更容易地包含静态资产,如图像或 CSS,而无需额外设置。然后,提到了权限提示中的堆栈跟踪。我不太确定这具体指什么,但它很可能通过在权限被拒绝或运行时出现问题时提供详细的错误信息来改进调试。
deno task命令据说得到了加速,这意味着任务已针对更好的性能和效率进行了优化,使其运行更快或更流畅。还提到了 Node.js 和 npm 兼容性改进。这可能意味着 Deno 现在可以更好地与现有 Node.js 项目配合使用,从而更容易迁移或与现有设置集成。
列出了
--allow-env通配符功能,这可能允许用户指定多个环境文件或更灵活地处理环境变量。格式化和 linting 已得到改进,因此开发人员可以期望在他们的项目中获得更好的代码质量检查和建议。
在 Jupyter notebook 中显示图像表明 Deno 现在支持直接在 Jupyter notebook 中渲染图像,这对于数据可视化和教育可能很有用。
使用
deno publish发布时覆盖版本,使用户可以更好地控制其包的发布方式,可能允许特定的版本控制策略。LSP 改进表明语言服务器已得到增强,使 Deno 成为 VS Code 等代码编辑环境的更好选择。
性能和生活质量改进是广泛的类别,但它们表明 Deno 2.1 致力于使该工具整体上更高效、更令人愉悦。
最后,提到了 V8 13.0,这可能指的是 V8 引擎的更新版本,为 Deno 的操作提供了更好的性能和功能。
综合来看,Deno 2.1 引入了多项关键增强功能,旨在提高开发人员的生产力、兼容性和性能。
Deno 2.1 引入了多项新功能,包括一流的 WebAssembly (Wasm) 支持、编译期间嵌入的资产文件、权限提示中的堆栈跟踪、经过加速的
deno task命令、改进的 Node.js 和 npm 兼容性、通配符环境变量文件支持、增强的格式化和代码检查、在 Jupyter Notebook 中显示图像、版本覆盖选项、LSP 改进、性能增强以及 V8 引擎的更新。
最后
我一直认为大型语言模型将是一种辅助工具,我使用 RAG 代理的实验不仅验证了这一点,还向我展示了在本地可以实现多少功能。使用 Deno 和像 LangChain 这样的框架,确实可以让你快速进行实验和微调。
能够创建一个完全由我控制的 AI 代理,使得将 AI 整合到解决方案中成为一个明确的可能性。我将继续为我的工作探索 RAG 系统,因为其应用是无限的:数据处理和分析、图像生成和解释、测试生成以及安全假设检查。