
Deno KV 内部:为现代 Web 构建数据库



Deno 旨在通过内置的现代工具、直接访问 Web 平台 API 以及通过 npm 导入模块的能力来简化 Web 和云开发。Web 应用通常需要一些持久化的应用程序状态。设置数据库涉及大量的配置步骤以及后续的 ORM 或其他系统的集成。
如果无需任何前期设置即可访问此类数据库,那会怎样?这正是 Deno KV 允许您做到的
const kv = await Deno.openKv();
const userId = crypto.randomUUID();
await kv.set(["users", userId], { userId, name: "Alice" });为什么构建 Deno KV?
Deno 运行时不仅可以在您的本地机器上以 deno 可执行文件的形式运行,还可以在我们的 Deno Deploy 云平台上运行,该平台允许您将 Deno 应用部署到全球多个区域。这种全球部署最大限度地减少了用户与应用计算之间的延迟,这可以极大提升您应用的性能。
我们知道我们想为 Deno 构建一个数据库,原因是一个我们从许多客户那里听到的非常简单的问题:除非您的应用程序数据也进行全球分发,否则您将无法利用通过分发计算获得的性能优势。
此外,由于 Deno 运行时旨在在单实例场景中本地运行,或在多实例场景中全球运行,我们为其中一种场景引入的任何 API 都应在另一种场景中同样出色地工作。这使得您可以轻松地在本地开发和测试您的应用,然后将其全球部署,而无需更改代码或添加任何配置。
这使我们为 Deno KV 设定了几个设计目标
- 可扩展性:一个分布式数据库,能够以高吞吐量处理大量数据
- 高性能:计算与数据库之间的高延迟往返次数最少,以最大限度地减少网络延迟的影响
- JavaScript 原生:一个旨在从 JavaScript 和 TypeScript 使用的数据库,其 API 原生使用 JavaScript 类型
- 原子事务:一个提供原子操作以确保数据完整性并支持复杂应用逻辑的数据库
- 在本地和全球无缝运行:一个在单实例和多实例场景中都能出色工作的数据库
因此,我们着手构建两个版本的 Deno KV 系统,它们具有相同的面向用户的 API。一个基于 SQLite 构建的 Deno KV 版本,用于本地开发和测试;以及一个分布式系统版本,用于生产环境(特别是在 Deno Deploy 上)。本文将介绍 Deno KV 生产环境分布式系统版本的实现。如果您对 Deno KV 的 SQLite 实现感兴趣,可以自行阅读其源代码,因为它是开源的。
FoundationDB:可扩展、分布式、灵活且生产就绪
我们选择在 FoundationDB 之上构建 Deno KV,它是 Apple 的开源分布式数据库,在 iCloud 和 Snowflake 中使用,因为它非常适合构建可扩展的数据库解决方案:它通过确定性模拟经过彻底验证,可扩展且高效,并提供事务性键值存储 API。
尽管 FoundationDB 提供了健壮分布式数据库的必要机制,但在将其转化为可在我们的 Deno Deploy 平台内无缝运行的 JavaScript 原生体验时,仍然存在一些挑战
- Deno KV 不仅在数据方面是多租户的,在配置方面也是如此。不同的用户有不同的复制设置、备份策略和吞吐量配额。FoundationDB 没有原生机制来处理这些。
- 我们希望 Deno KV 完全原生支持 JavaScript 并使用 JavaScript 类型。例如,Deno KV 可以存储有符号的可变长整数(bigint),我们希望支持对这些类型进行原子求和操作,但 FoundationDB 本身不支持对可变长整数的原子求和。
- 为了最大限度地减少计算与数据之间无限延迟的可能性,Deno KV API 的设计围绕非交互式事务(即原子操作),而 FoundationDB 提供乐观的交互式事务。即使可行,在 FoundationDB 之上实现 Deno KV API 也会产生不必要的开销。
这些限制促使我们在 FoundationDB 之上设计了一个新系统,我们称之为“事务层”。它以分布式方式执行事务处理和跨区域数据复制,同时仍然将分布式数据库的复杂方面委托给 FoundationDB:分片、集群内同步复制、确保事务的可序列化和线性化处理,以及持久存储数据。
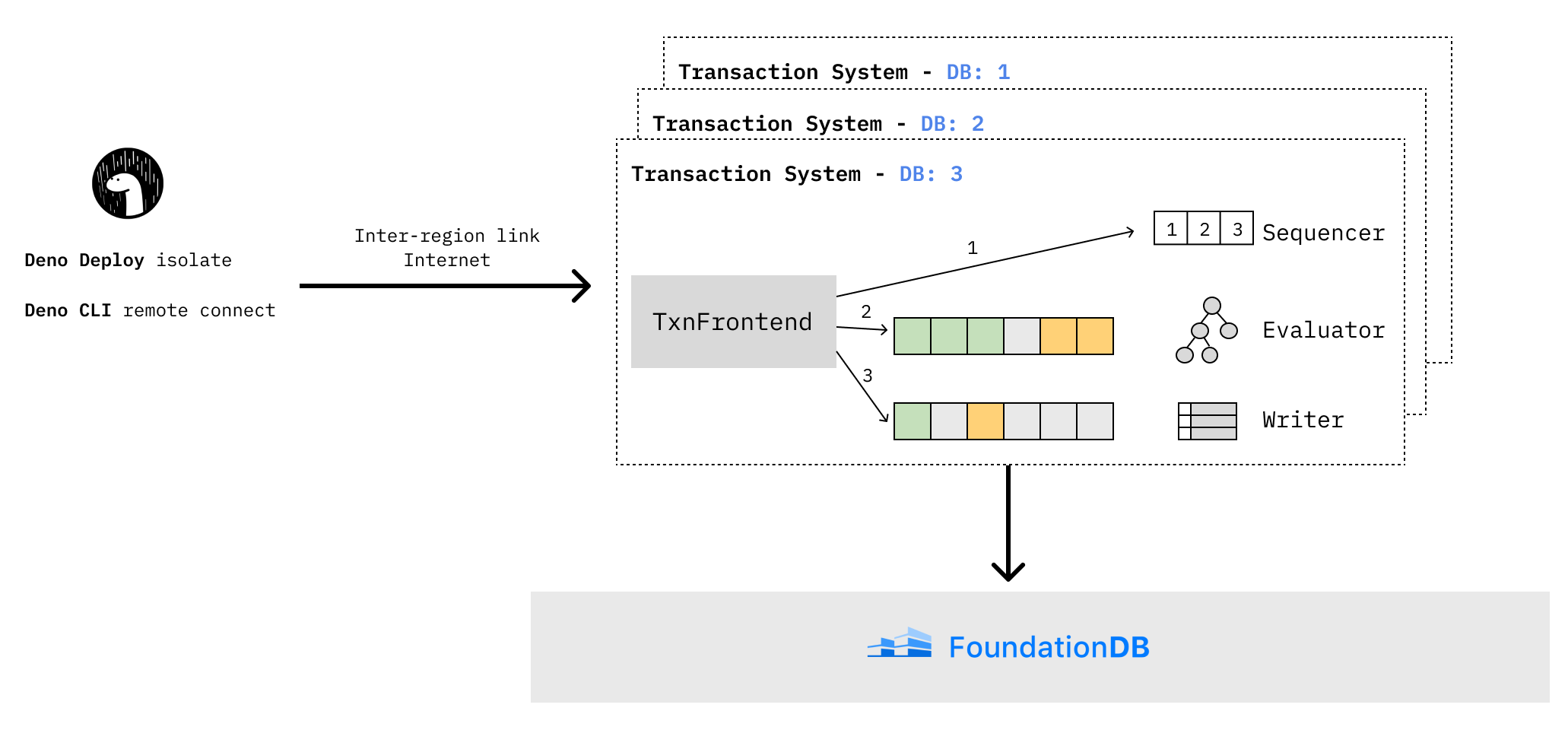
让我们深入探讨我们如何为原子性、最小延迟和高并发性设计事务层。
具有最小网络请求的原子操作
原子操作通常是交互式事务,因为它们需要多次请求数据库才能保证原子性。

然而,对于全球分布式数据库来说,交互式事务成本很高。如果一个写操作需要在计算服务器和数据库区域之间进行多次往返,那么执行多个写操作的 Web 应用可能会遇到高网络延迟。

为了最大限度地减少延迟,我们将全球 Deno KV 设计为非交互式——所有事务应在一两次网络往返内完成。我们通过将所有原子写入操作封装到由条件、写入命令和无冲突变异组成的“集合”中来实现这一点
- 条件:为了保证原子性,我们检查键的
versionstamp。如果在操作执行时为假,则整个操作将被丢弃 - 写入命令:对键进行的任何
.set()或.delete()操作 - 无冲突变异:任何接受键的旧值并返回新值的函数。例如,变异类型
.sum()将提供的操作数添加到旧值
为了创建这个“集合”,Deno KV 要求所有原子操作都遵循 .atomic() 进行链式调用
const kv = await Deno.openKv();
const change = 10;
const bob = await kv.get(["balance", "bob"]);
const liz = await kv.get(["balance", "liz"]);
if (bob.value < change) {
throw "not enough balance";
}
const success = await kv.atomic()
.check(bob, liz) // balances did not change
.set(["balance", "bob"], bob.value - change)
.set(["balance", "liz"], liz.value + change)
.commit();这种原子操作的 API 设计确保了计算与数据库之间的最小往返次数,从而实现最佳性能。
基于 FoundationDB 的无锁系统构建
数据库中的“锁”是确保数据完整性的机制。这些机制只允许一个事务修改或访问数据。相比之下,无锁系统允许并发进程访问和修改数据,在不牺牲数据完整性的前提下提供并行性和可扩展性。
尽管 FoundationDB 使用无锁设计,但简单地将冲突检查机制委托给 FoundationDB 会导致延迟问题,特别是当原子操作执行无法下推到底层数据库原语的无冲突变异时。
await kv.atomic().sum(["visitor_count"], 1n).commit();为了最大限度地提高原子操作的性能和并发性,我们构建了 Deno KV 事务层,它管理原子操作的全局顺序。对于此事务层接收的每个事务
- 事务由序列器(sequencer)分配一个事务序列号(“TSN”),这是一个单调递增的整数,其顺序与原子操作的线性化顺序等效
- 事务与其他事务一起批量处理,评估器(evaluator)从中构建一个图,描述所有条件、写入命令和无冲突变异之间的关系。然后,评估器以最大并发度处理该图,直到每个图节点的值都已知。
- 事务最终由写入器(writer)提交到 FoundationDB
序列器、评估器和写入器是相互独立的组件,它们协同工作以处理大量操作。但我们如何从这个管道中榨取更多性能呢?
通过推测执行加速操作
推测执行是一种最大化指令处理吞吐量的技术,其中会执行一些可能不需要的工作。
Deno KV 的事务层使用这种技术,其中事务以集中方式分配全局顺序,但在其他地方进行乱序处理。事务的输出在持久化到磁盘之前,会在未来的事务中进行推测性使用。事务的效果只有在提交到 FoundationDB 后才能对外可见。
该机制的核心数据结构是“事务重排序缓冲区”,它管理要处理的事务流
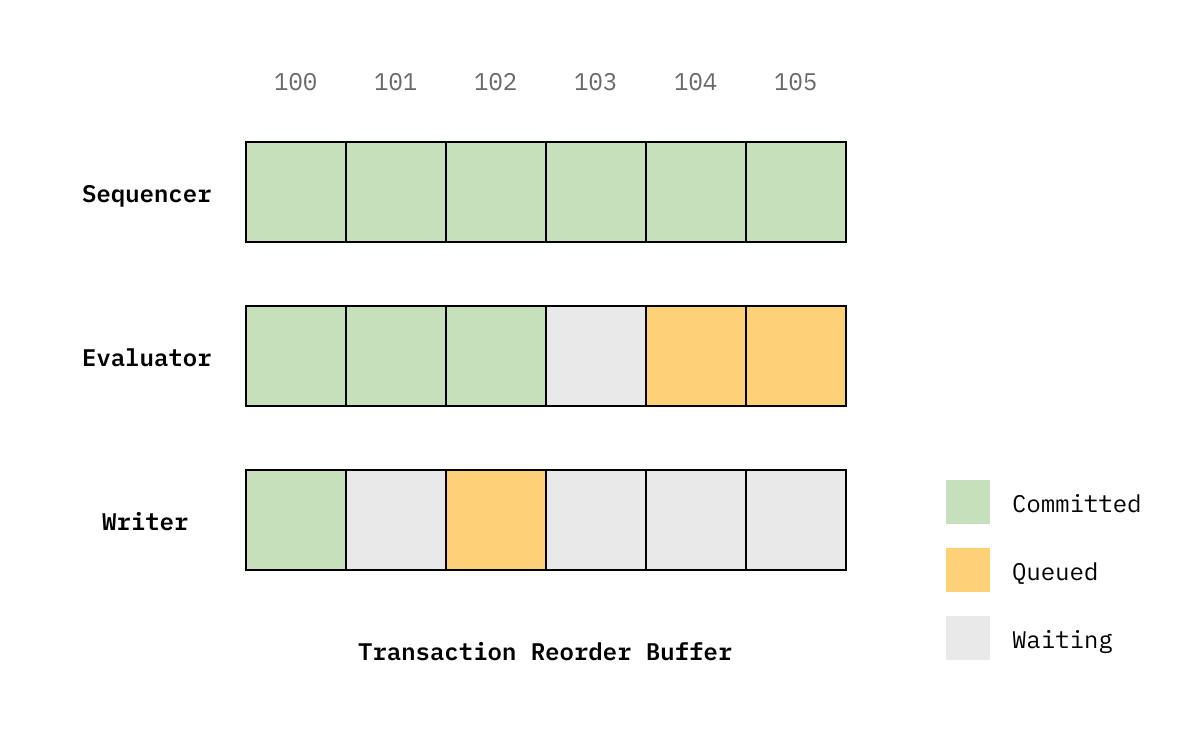
序列器负责发出在每个 epoch 内连续的单调整数。尽管每个 KV 数据库都只有一个序列器,但序列化操作非常廉价,因为它只是对内存中的原子计数器进行增量操作。序列器也只需要等待前一个序列器被提交(绿色)。
评估器批量处理事务。在每个批次中,评估器构建一个“数据流子图”,描述所有条件、写入命令和无冲突变异之间的关系。这是一个操作图,用于确定事务是成功还是失败,以及操作的最终值。然后,评估器以最大并发度处理该子图,直到每个图节点的值都已知。
为了更好地说明这个数据流子图(它在无锁系统中实现了高并发),我们来看一个例子
// Client 1 is updating the login of user UID1 from “alice” to “bob”
await kv
.atomic()
.check({ key: ["users", UID1], versionstamp: V1 })
.check({ key: ["user_by_login", "bob"], versionstamp: null })
.set(["users", UID1], user1)
.set(["user_by_login", "bob"], UID1)
.delete(["user_by_login", "alice"])
.commit();
// Client 2 is creating a new user with login "bob"
await kv
.atomic()
.check({ key: ["user_by_login", "bob"], versionstamp: null })
.set(["users", UID2], user2)
.set(["user_by_login", "bob"], UID2)
.commit();上述两个操作相互冲突,因此只有一个能成功。假设第二个操作被分配了比第一个更大的 TSN,那么从包含这两个操作的评估器批次构建的数据流子图将是这样的
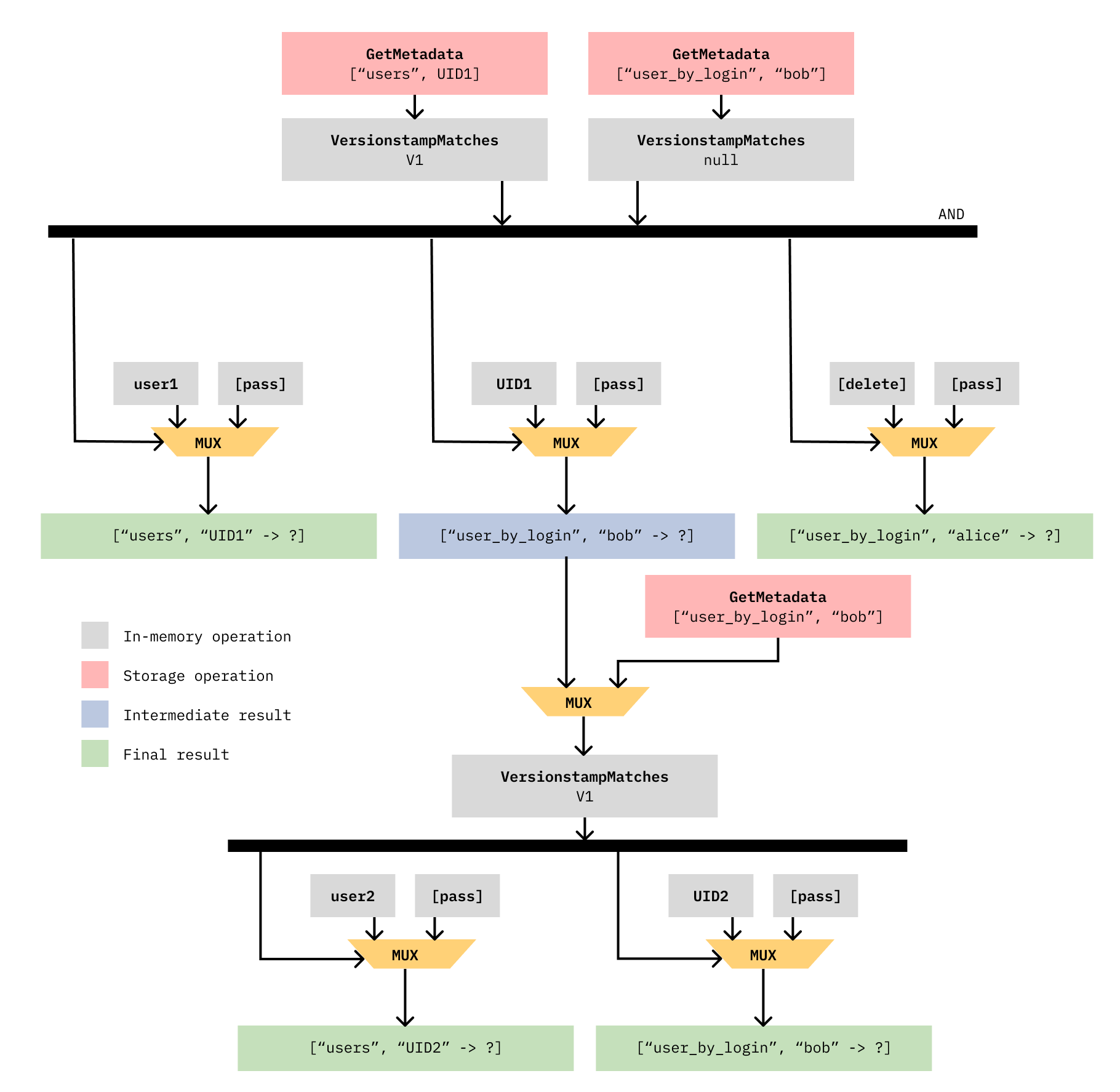
这个图看起来有点复杂——让我们来逐一解释。
最上面一行(带有两个 GetMetadata 框)代表来自客户端 1 的两个 .check() 命令(.check({ key: ["users", UID1], versionstamp: V1 }) 和 .check({ key: ["user_by_login", "bob"], versionstamp: null }))。它们流入水平的 AND 线,因为两个检查都需要成功。
从顶部数第二行(在水平 AND 线下方)显示了三个 MUX(即多路复用器逻辑门)操作,它们代表客户端 1 的 .set() 和 .delete() 命令。每个 MUX 门上方显示了每个命令的输入
.set(["users", UID1], user1)->user1和[pass].set(["users_by_login", "bob"], UID1)->UID1和[pass].delete(["user_by_login", "alice"])->[delete]和[pass]
请注意,[pass] 简单地表示保留旧值,因为当 MUX 门可以接受两个输入时,这些命令只有一个输入。
虽然第一个和第三个 MUX 门的输出是绿色(最终结果),但中间的那个是蓝色(中间结果)。请记住,最终结果不是一个值;它是一个写入函数,其输入(在图中用 ? 表示)将在创建此图后进行评估。
那么为什么会有中间结果呢?这是因为客户端 2 的 .check() 需要对共享键 ["user_by_login", "bob"] 断言 versionstamp。为了解决这个中间结果并得到最终结果,我们使用另一个 MUX 门,它接收中间结果和 ["user_by_login", "bob"] 的 GetMetadata。
这会将我们带到底部一行,其中有两个 MUX 门代表客户端 2 的 .set() 命令(.set(["users", UID2], user2) 和 .set(["user_by_login", "bob"], UID2))。从这些门,我们可以获得最终结果。
评估器从一批操作中创建此数据流子图后,它会计算结果并将其缓存在内存中。这些内存中的结果可用于后续的评估器批次,进行更多的推测执行,因为这些结果可能尚未在 FoundationDB 中可见。这些内存中的结果将随着已知提交版本的推进而被丢弃,或者当我们确定可以从 FoundationDB 读取数据时被丢弃。
最后,写入器启动以持久化变异。写入器也批量处理事务。在每个批次中,写入器将事务的结果写入底层数据库,并执行其他各种任务,例如写入复制日志和将键排队等待过期。
将推测执行与序列器-评估器-写入器流水线结合使用,有助于最大限度地提高并发性和性能,同时保持原子操作的数据完整性。
结论
Deno KV 的开发是基于现代 Web 开发的需求和 FoundationDB 带来的可能性。我们一直以来都强调功能性、可扩展性以及 JavaScript 的无缝集成。通过利用 FoundationDB 的无锁系统并引入事务层和推测执行等功能,我们旨在兼顾性能和用户体验。
然而,技术和需求都在不断发展。尽管我们坚信 Deno KV 的基础和原则,但我们也深知技术领域的持续进步。我们与 Deno KV 的旅程仍在继续,由我们的愿景和来自用户社区的宝贵反馈共同塑造。
展望未来,我们致力于改进 Deno KV,响应新兴需求,并确保其在快速发展的 Web 和云环境中的适应性。我们欢迎所有开发者尝试 Deno KV,更重要的是,分享能够指导其未来方向的见解和反馈。
注册 Deno Deploy 即可免费访问零配置的全球分布式数据库。