
我们如何构建 JSR

我们最近推出了 JavaScript 注册表 - JSR。这是一个为 JavaScript 和 TypeScript 设计的新注册表,旨在为包作者和用户提供比 npm 显著更好的体验。
- 它原生支持发布 TypeScript 源代码,用于自动生成您包的文档。
- 它默认安全,支持从 GitHub Actions 无令牌发布,并使用 Sigstore 支持包溯源。
- 它使用我们的“JSR 评分”来评估包,以便消费者“一目了然”地了解包的质量。
我们知道,JSR 只有与现有的 npm 生态系统互操作才能获得采用。以下是 JSR 需要满足的“npm 互操作性”要求:
- JSR 包可以被任何使用
node_modules/文件夹的工具无缝消费。 - 您可以在 Node 项目中逐步采用 JSR 包。
- npm 包可以从 JSR 包中导入,JSR 包也可以从 npm 包中导入。
- 大多数用 ESM 或 TypeScript 编写的现有 npm 包都可以轻松发布到 JSR——只需运行
npx jsr publish。 - 您可以将您喜欢的 npm 兼容包管理器,如
yarn或pnpm,与 JSR 一起使用。
JSR 的开放测试版发布受到了社区的热烈欢迎,我们已经看到了一些优秀的包被发布,例如类型安全的验证 & 解析库 @badrap/valita 和多运行时 HTTP 框架 @oak/oak。
但这篇博客文章不是关于您为什么应该使用 JSR。它是关于我和 JSR 团队的其他成员如何经过数月的时间,构建 JSR 以满足现代、高性能、高可用 JavaScript 注册表的技术要求。这篇文章涵盖了 JSR 的几乎每个部分。
- 技术规格概述
- 最小化 jsr.io 网站的延迟
- 构建现代发布流程(又称告别探测!)
- 以 100% 的可靠性提供模块服务
- 就这样?
我将尝试不仅解释我们 如何 做某事,而且解释我们 为什么 这样做。让我们深入探讨。
技术规格概述
要使 JSR 成为一个成功的现代 JavaScript 注册表,它必须具备 许多 功能:
- 一个全球 CDN,用于提供包源代码和 NPM tarball。
- 一个供用户浏览包和管理他们在 JSR 上的存在的网站。
- 一个供 CLI 工具发布包的 API。
- 一个在发布期间分析源代码以检查语法错误或无效依赖项、生成文档和计算包评分的系统。
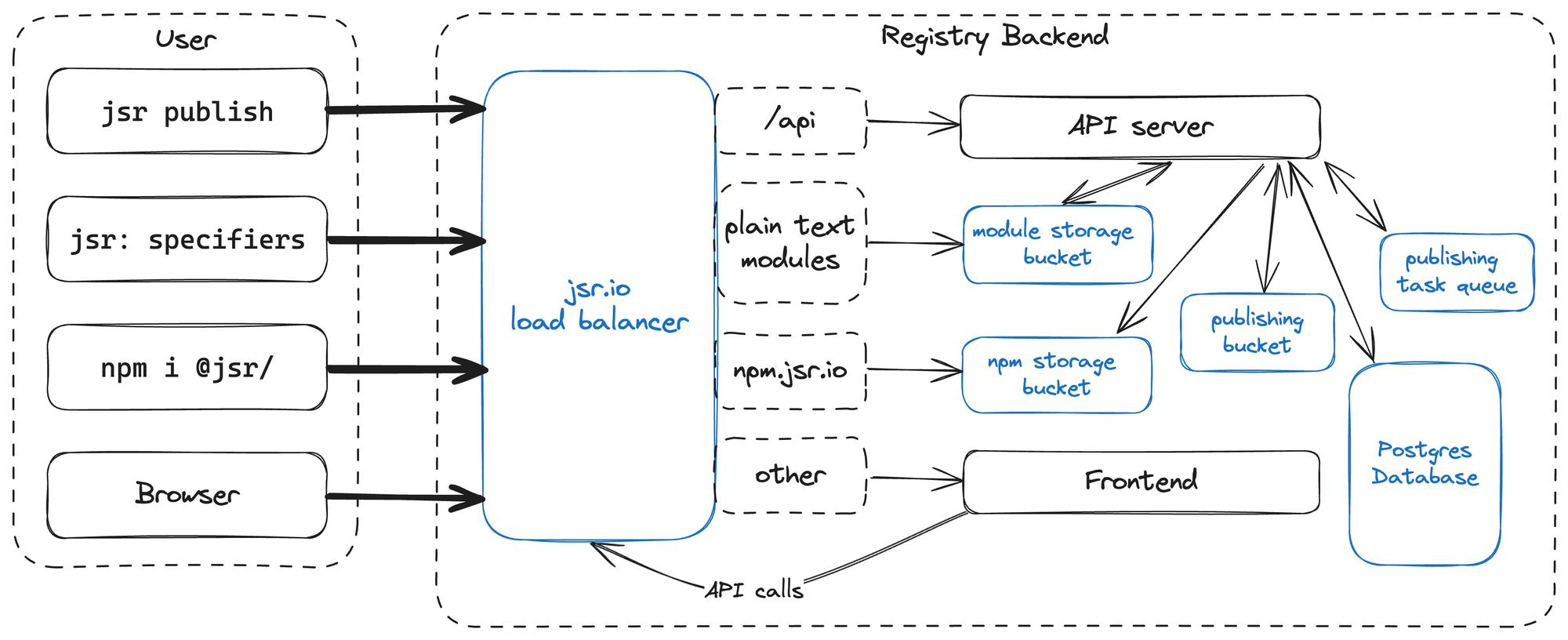
构建一个满足所有这些条件的事物的挑战在于它们各自具有不同的约束。
例如,全球 CDN 必须拥有近乎 100% 的正常运行时间。即使只有 0.1% 的用户下载包失败,也是不可接受的。如果包下载失败,那意味着 CI 运行中断,开发人员困惑,以及非常糟糕的用户体验。任何规模可观的项目都将在某个时候遇到 CI 不稳定问题——我不想再增加这种麻烦了😅。
另一方面,如果用户在被邀请后 10 分钟才收到范围邀请邮件,那么问题就小得多。这虽然不是很好的用户体验(我们仍然尽量避免这种情况),但它不是一个需要半夜呼叫值班工程师的严重缺陷。
由于可靠性是 JSR 的核心部分,这些权衡决定了 JSR 及其各种组件的架构方式。每个部分都有不同的服务水平目标(SLOs——通常定义可靠性的方式):我们对提供包源代码和 NPM 包的服务目标是 100% 正常运行时间,而其他服务(如我们的数据库)则目标更为保守的 99.9% 正常运行时间。在本文中,我们将把 SLO 作为起点,来确定我们如何设计系统的一个部分。
大部分数据使用 Postgres
JSR 使用高可用性 Postgres 集群来存储大部分数据。我们有用于 users、scopes 或 packages 等显而易见的数据表。但我们也有更大的数据表,例如我们的 package_version_files 表,其中包含上传到 JSR 的所有文件的元数据,如 path、hash 和 size。由于 Postgres 是一个关系型数据库,我们可以使用 JOINs 组合这些表来检索各种有趣的信息:
- 这个用户消耗了多少存储空间?
- JSR 包中有多少文件是重复的?
- 创建者注册 JSR 后一小时内发布了哪些包?
我们使用出色的 sqlx Rust 包 来处理数据库迁移。您可以在 GitHub 上查看创建 JSR 数据库的所有迁移。
我们的 Postgres 数据库托管在 Google Cloud 上(就像 JSR 的其余部分一样!)。我们过去在使用 Google Cloud 方面有很好的经验,所以我们决定在这里再次使用它。Google Cloud 为 Terraform 提供了非常好的工具和文档,Terraform 是我们用于部署 JSR 的基础设施即代码工具(这本身可以写一篇完整的博客文章)。
API
我们的 API 服务器位于 Postgres 数据库上方。JSR 不直接向客户端公开 Postgres 数据库。相反,我们通过 HTTP REST API 以 JSON 格式公开数据库中的数据。API 请求可以来自多种不同类型的客户端,包括用户的浏览器,或者来自 jsr publish / deno publish 工具。
JSR API 服务器是用 Rust 编写的,使用了 Hyper HTTP 服务器。它通过 sqlx Rust crate 与 Postgres 数据库通信。该服务部署在 Google Cloud Run 上,位于一个区域,紧邻 Postgres 数据库。
除了在数据库和 JSON API 接口之间代理数据外,API 服务器还强制执行身份验证和授权策略,例如要求只有范围成员才能更新包的描述,或者确保只有正确的 GitHub Actions 作业才能用于发布包。
归根结底,API 服务器是一个相对标准的,可以在数百个其他 Web 应用程序中以非常相似的形式存在的服务。它与 SQL 数据库交互,使用电子邮件服务(在我们的例子中是 Postmark)发送电子邮件,与 GitHub API 通信以验证仓库所有权,与 Sigstore 通信以验证发布证明,等等。
最小化 jsr.io 网站的延迟
如果您正在为人类用户编写服务,您很快就会发现大多数人类实际上不想手动使用 curl 调用 API。因此,JSR 有一个 Web 前端,它允许您执行 API 公开的每一个操作(除了发布包——稍后详细介绍)。
为了让 jsr.io 网站感觉快速流畅,我们使用 Fresh 构建了它,Fresh 是 Deno 内部构建的现代“服务器端优先渲染”Web 框架。这意味着 JSR 网站上的每个页面都是在您附近的 Google Cloud 数据中心运行的 Deno 进程中按需为您渲染的。让我们探讨 Fresh 用于确保网站访客获得最佳体验的一些方法。
岛屿渲染以提高性能
Fresh 的独特之处在于,与其他 Web 框架(如 Next.js 或 Remix)不同,它不会在客户端和服务器上同时渲染整个应用程序。相反,每个页面始终完全在服务器上渲染,只有被标记为交互的部分才在客户端渲染。这被称为“岛屿渲染”,因为我们在服务器渲染内容的大海中拥有小的交互岛屿。
这是一种非常强大的模型,它使我们能够为所有用户提供极快的页面渲染,无论他们的地理位置、互联网速度、设备性能和内存可用性如何,并提供非常好的交互式用户流程。例如,由于我们的岛屿架构,JSR 网站仍然可以支持“即时搜索”和表单提交前的客户端范围名称验证,即使在使用服务器端渲染的情况下。所有这些都无需向客户端发送 Markdown 渲染器、样式库或组件框架。
这确实很有效。
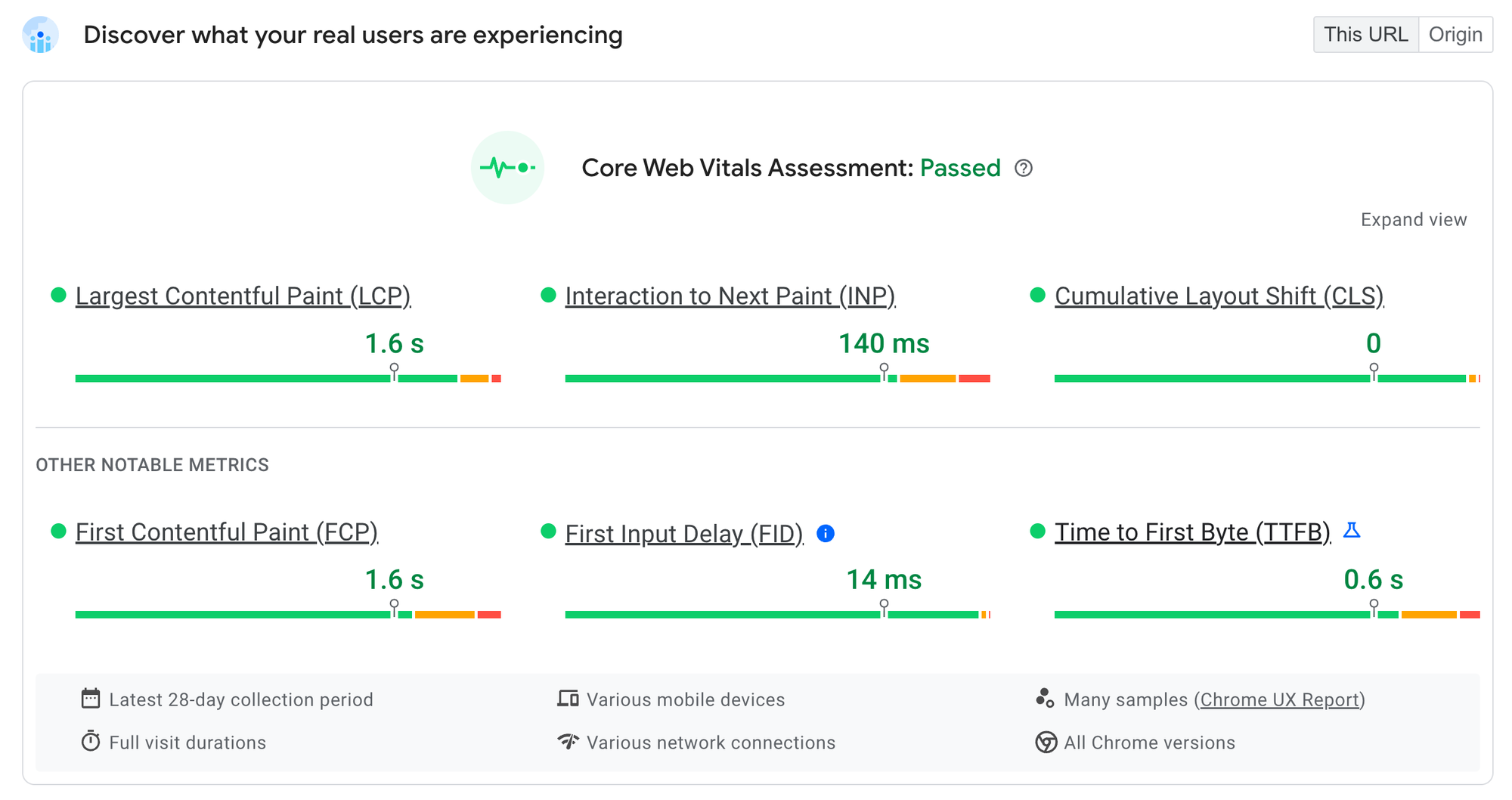
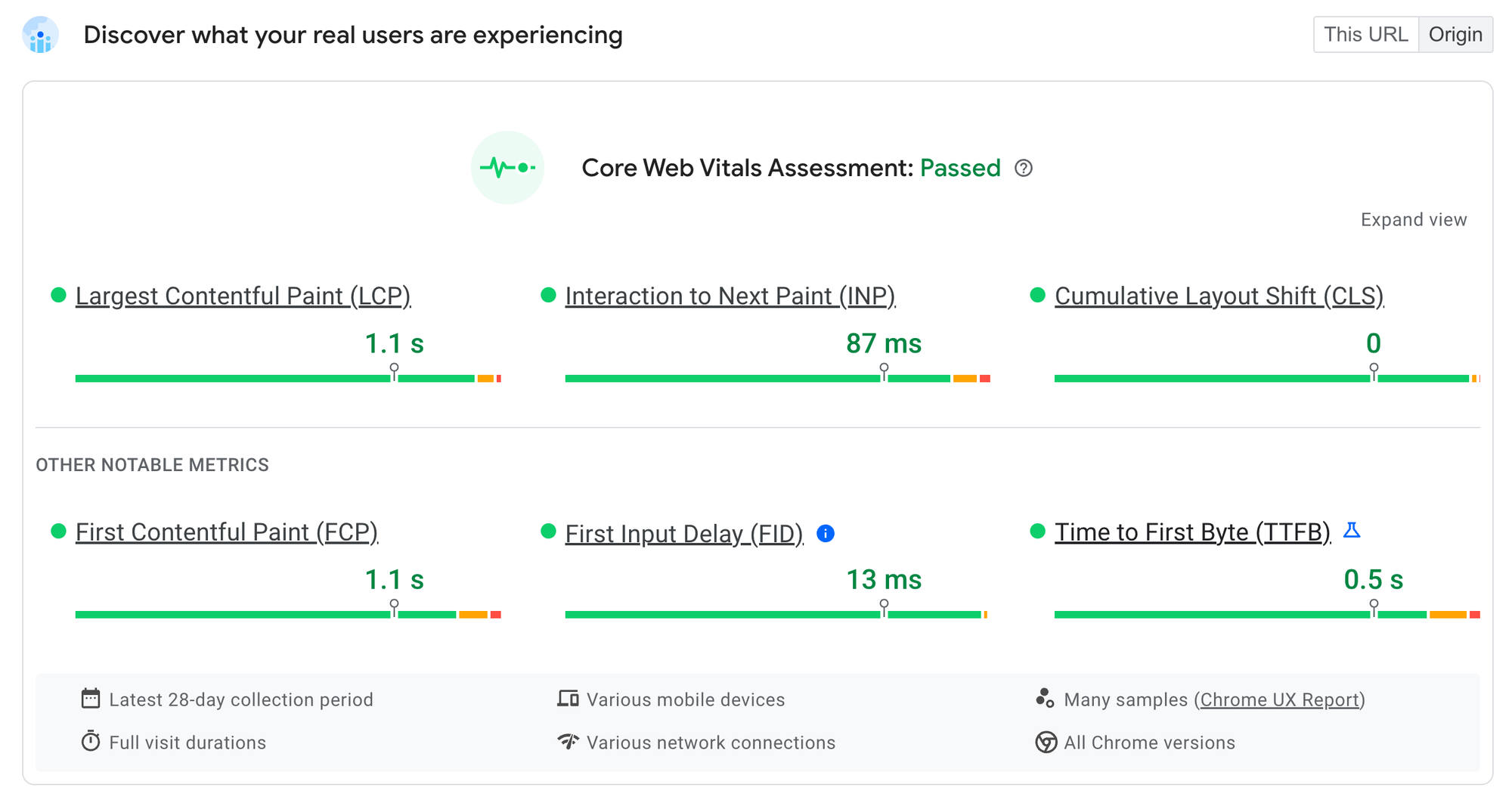
来自 Chrome UX 报告的真实用户数据(Chrome 在后台收集的匿名性能统计信息)显示,https://jsr.deno.org.cn 在各种设备和网络上都具有出色的性能。特别令人兴奋的是,新指标“交互到下一帧渲染时间”(INP)的得分非常出色,该指标衡量主线程在渲染方面的争用程度,并代表交互的“感觉”速度。由于 Fresh 的岛屿架构,JSR 在这些指标上表现出色。
优化首字节时间 (TTFB)
您可能还会注意到 TTFB 性能。TTFB 指标代表“首字节时间”的 75 百分位——从您在 URL 栏中按下 Enter 到浏览器接收到服务器响应开始之间的时间。我们的 TTFB 分数 0.5 秒非常出色,特别是对于动态服务器端渲染的网站。(服务器渲染的网站往往有更高的 TTFB,因为它们等待服务器上的动态数据,而不是在客户端提供静态外壳,然后再从客户端获取动态数据。)
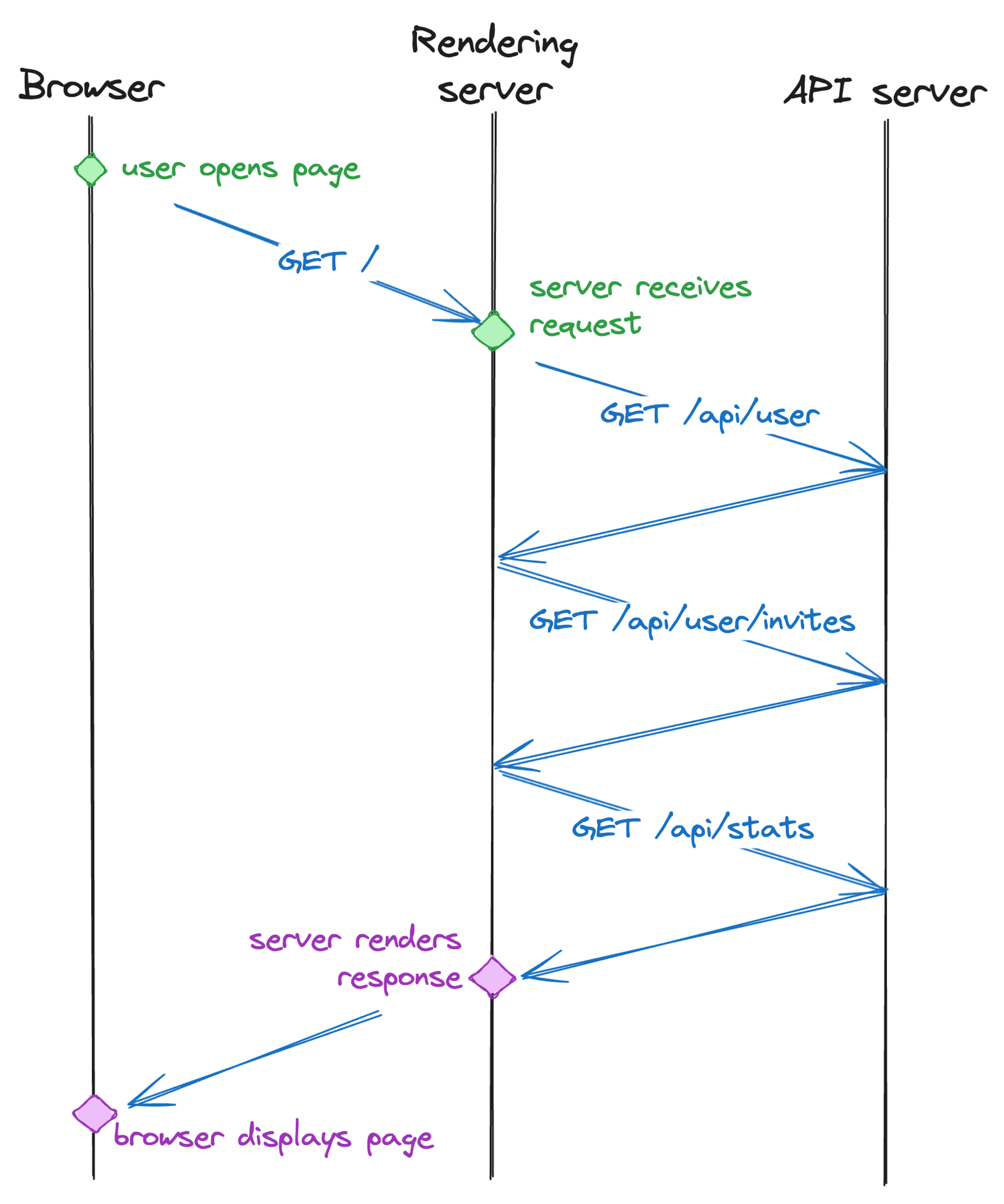
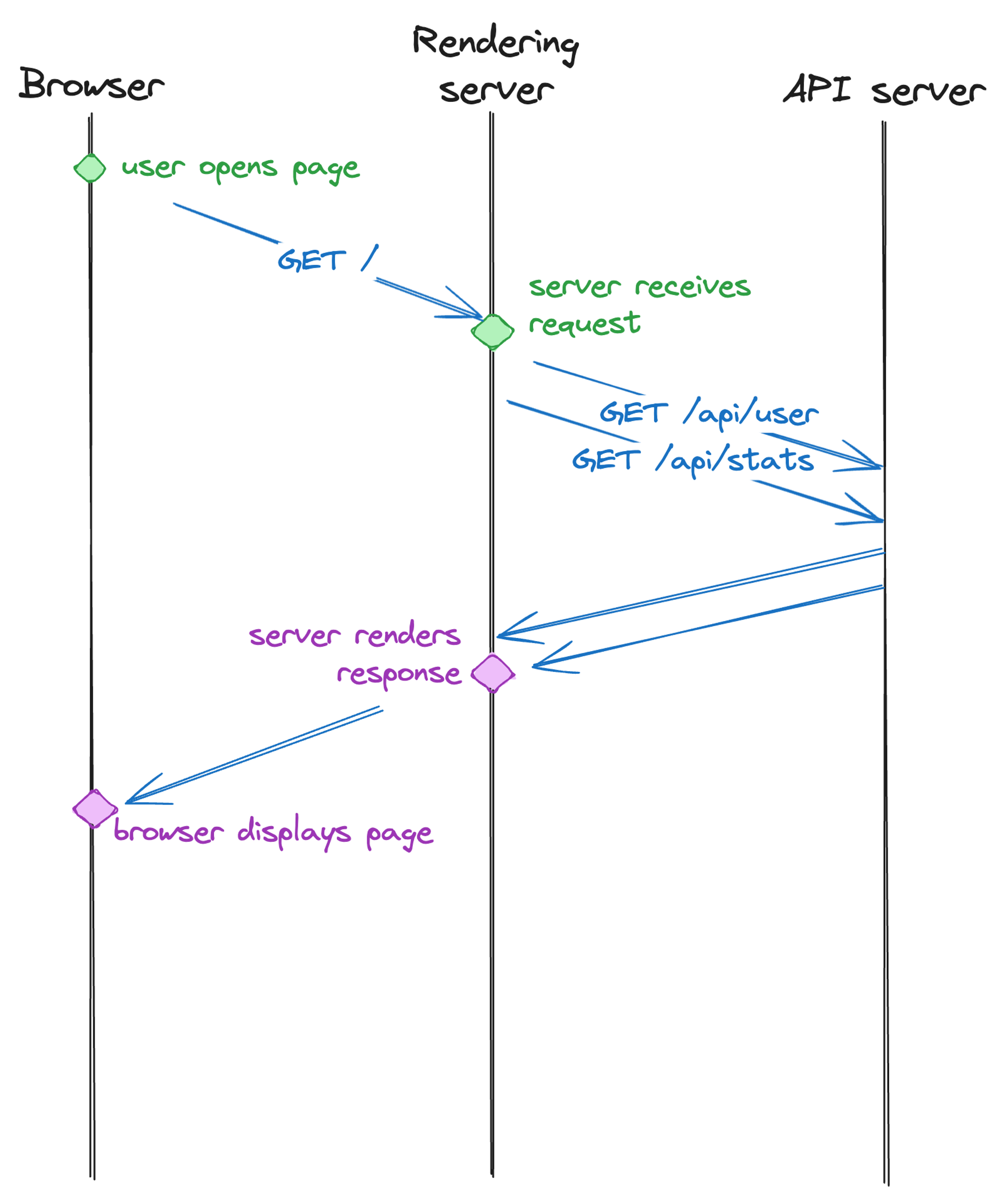
我们花了很多时间优化 TTFB,这对于服务器端渲染的页面来说是一个真正的挑战。由于整个页面渲染被阻塞,直到所有数据都存在于服务器上,因此服务器检索所需所有数据所需的时间需要尽可能缩短。在我们 JSR 工作的最初几周,我经常收到来自印度和日本同事的报告,称 JSR 包页面加载速度慢得令人难以忍受——一个简单的包设置页面需要数秒。
我们设法将此问题归结为渲染页面的服务器和我们的 API 服务器之间的请求瀑布。我们首先会获取用户配置文件,然后获取包元数据,然后获取用户是否是该范围的成员,等等。由于我们的 API 服务器托管在美国(离印度很远),甚至互联网也需要遵守光速等物理限制,因此我们需要数秒才能获得渲染所需的所有数据。
我们现在已经到了 JSR 网站上没有一条路由需要在渲染服务器和 API 服务器之间进行多次网络往返的程度。我们设法并行化了许多 API 调用,在其他情况下,以微妙的方式改进了 API,使其不再需要多次请求。例如,最初的包页面会首先获取包版本列表,找出最新版本,然后获取该版本的 readme。现在,您可以直接告诉返回 readme 的 API 端点,您想要“最新”版本的 readme,并且它可以从其位于同一位置的数据库中快速找出最新版本。
尽可能使用 <form>
尽可能依赖内置浏览器 <form> 提交可能看起来很奇怪。(我们甚至在不寻常的地方使用 <form>,例如范围成员列表中的用户旁边的“移除”按钮。)然而,这样做可以显著减少我们必须编写、交付给用户和审计可访问性的代码量。
可访问性是网页开发的一个重要方面,而使用更多内置浏览器原语可以显著减少您自己完成工作以获得良好结果的工作量。
我还没提到所有这些都是开源的吧?JSR 前端可能是最容易贡献的部分。
git clone https://github.com/jsr-io/jsr.git
cd jsr
echo "\n127.0.0.1 jsr.test" >> /etc/hosts
deno task prod:frontend这将为您启动一个本地前端副本,供您玩转,它已连接到生产 API。如果您在 frontend/ 文件夹中进行更改,您在 http://jsr.test 的本地前端将自动重新加载。您甚至可以使用您站点的本地副本管理您的生产 JSR 服务中的范围和包!
构建现代发布流程(又称告别探测!)
我们已经谈了很多关于管理包元数据(API 服务器)和查看这些元数据(前端),但实际上——如果不能发布包,包注册表又算什么呢?
构建一个必须与 npm 互操作的现代 JavaScript 注册表,意味着能够接受各种不同类型的包。模块作者应该能够发布:
- 用带有
package.json的 TypeScript 编写的现有 NPM 包 - 使用
import_map.json为 Deno 编写的包 - 甚至是一个重新导出从 npm 导入的包的单个 JS 文件
构建一个支持接受各种包的注册表的挑战意味着我们必须理解和支持各种模块解析方法:
- 文件使用其实际扩展名导入(导入 TS 文件使用
.ts) - 文件根本没有扩展名
- 文件使用错误的扩展名(
.js导入实际上指的是带有.ts扩展名的 TS 文件) - 在导入映射中解析的裸标识符
- 通过 package.json 解析的裸标识符
- ……等等
尽管支持发布各种包存在这些复杂性,但我们 **很早就知道 JSR 包的消费者不应该需要了解这些错综复杂的差异。我们正在努力将生态系统推向一个一致、大大简化的方向:仅限 ESM 和非常明确的解析行为。** 为了为包消费者提供世界一流的开发者体验,JSR 必须确保下载的代码格式一致。
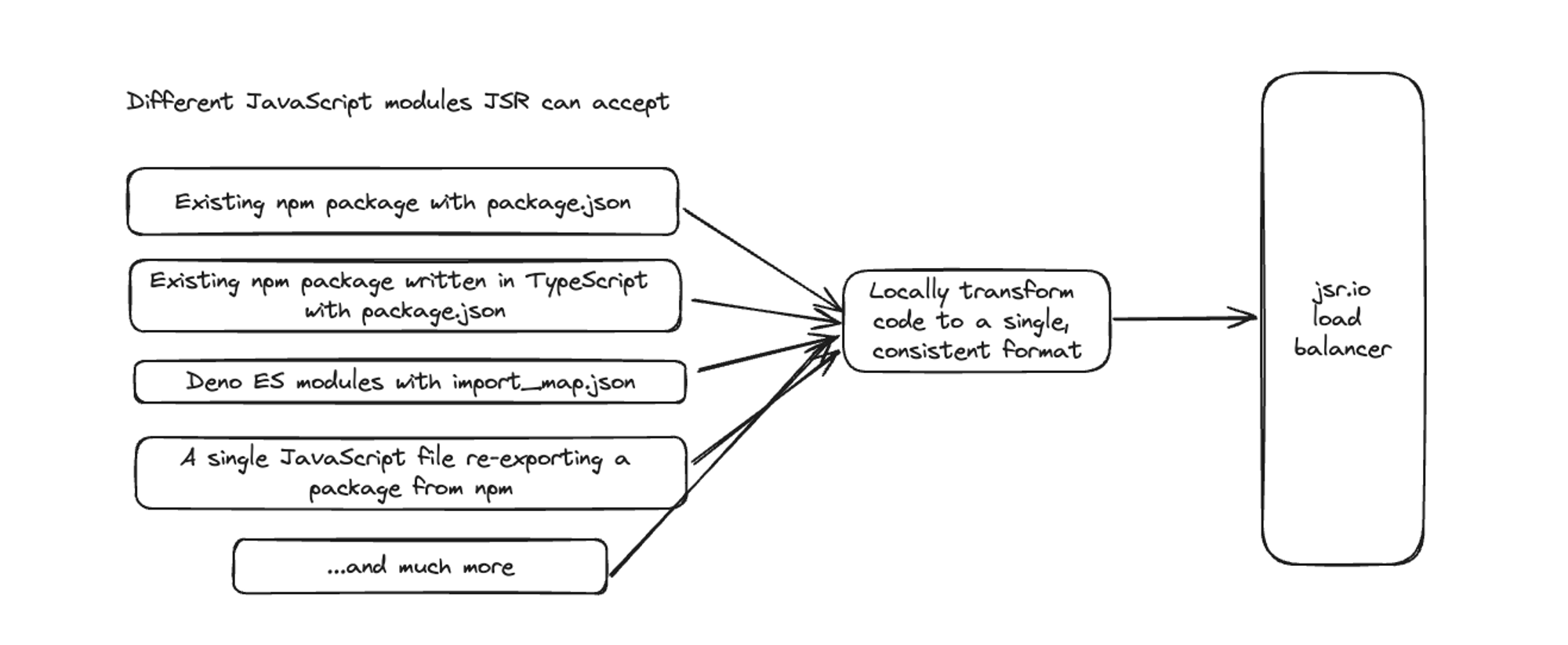
那么,我们如何在支持接受各种包的同时,仍然提供简单标准化的包消费体验呢?
当作者发布到 JSR 时,我们会自动对其进行“修复”,将其转换为注册表的一致格式。作为包作者,您无需知道、关心或理解它正在发生。但这种代码转换会加速并简化注册表。
那么,问题是这种“一致标准”格式是什么?
告别探测
在深入探讨之前,先简单聊聊“探测”。(哦……我光是说出来就发抖。) 探测是指给出不明确的指示,然后对方 尝试多种方法 直到某种方法奏效的做法。困惑吗?这里有一个例子。
想象一下你在超市工作,今天刚把水果上架。回家后,你决定想吃菠萝。你派人去超市买一些,但你没有告诉他们买菠萝,而是说:“给我买任何有库存的、以字母‘p’开头的水果,我的优先顺序是:木瓜、梨、菠萝、百香果、桃子。”
你的跑腿员去了超市的水果区开始寻找。今天没有木瓜。梨?也没有。但看啊——菠萝!他们抓了一些,胜利地回到你身边。
但那是社区杂货店,在那里你可以一目了然地看到整个水果陈列,所以检查水果很快。如果我们是在一个批发水果市场呢?每个大陆的水果现在都分别放在一个巨大的仓库的各自区域里。在木瓜区、梨区和菠萝区之间走动需要 几分钟。“探测”水果在这里完全行不通,因为它耗时太长,变得不可行。
那么,这种笨拙的水果购买方式如何与一致的标准代码格式联系起来呢?很多解析算法都存在探测问题:import './foo' 需要检查是否存在名为 ./foo/index.tsx、./foo/index.ts、./foo/index.js、./foo.tsx、./foo.ts、./foo.js,甚至只是 ./foo 的文件。作为包作者,您知道要解析到哪个文件。但您却让解析器进行了一场有趣的“尝试打开一堆文件看看它们是否存在”的冒险。哎呀。
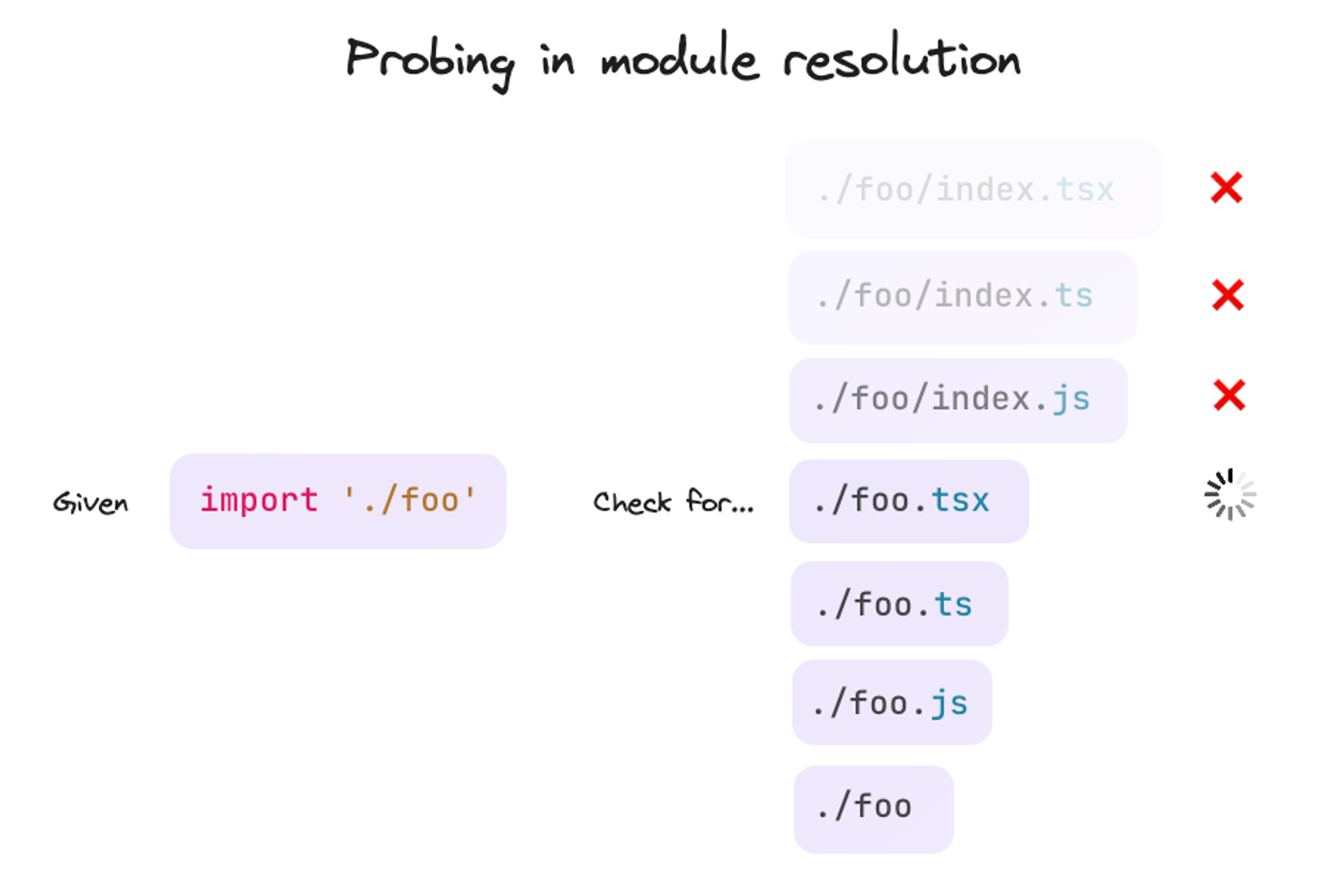
当您在本地文件系统上进行此操作时,性能通常可以接受。在现代 SSD 上读取文件需要几百纳秒。但在网络驱动器上“探测”——速度已经慢得多。而通过 HTTP——每次读取调用您都要等待几十毫秒。这对于包中的数百个文件来说是完全不可接受的。
因为 JSR 包不仅可以从文件系统导入,还可以使用 HTTP 导入(如浏览器和 Deno),所以探测是完全不可行的。(巧合的是,您现在也知道为什么浏览器永远无法像 Node 那样支持 node_modules/ 解析:探测太多了。)
在 publish 期间本地重写导入语句以消除探测
既然探测已被排除,那么供最终用户和 JSR 使用的一致标准格式必须遵循以下一个主要规则:
只给定模块的标识符和内容,您就可以准确地确定从该包中导入的所有文件的确切名称,以及所有外部包的名称和版本约束。
实际上,这意味着我们不能依赖 package.json 来解析依赖项,并且所有相对导入都必须具有明确的扩展名和路径。因此,为了支持接受广泛和多样的包,我们首先必须在代码到达 JSR API 层之前对其进行重写。
当您调用 jsr publish 或 deno publish 时,发布工具会检查您的代码,探测 package.json、导入映射以及您用于配置解析的任何其他内容,然后遍历您包中的所有文件,从 jsr.json 中的 "exports" 开始。然后,它会查找任何需要探测才能解析的导入,并将其重写为不需要探测的一致格式。
- import "./foo";
+ import "./foo.ts";- import "chalk";
+ import "npm:chalk@^5";- import "oak";
+ import "jsr:@oak/oak@^14";所有这些都在内存中发生,包作者无需看到或知道它正在发生。这种将本地代码转换为一致格式的转换是实现现代化、灵活的发布体验的魔法,作者可以以他们想要的任何方式编写代码,而用户可以以简单、标准化的方式使用包。
使用后台队列提高可用性
接下来,发布脚本将所有文件放入一个 .tar.gz 文件中。在让用户交互式地验证发布后(这本身可以成为一篇完整的博客文章 👀),它将 tarball 上传到 API 服务器。
然后,API 服务器会执行一些初始验证,例如检查 tarball 是否小于允许的 20MB,以及您是否有权发布此版本。然后,它将 tarball 存储在存储桶中,并将发布任务添加到后台队列。
为什么要将其添加到队列而不是立即处理 tarball?为了可靠性。
可靠性的一部分是处理流量峰值。由于发布是一个密集型过程,需要大量的 CPU 和内存资源,因此一个大型的单体仓库同时发布 100 个不同包的新版本可能会导致整个系统运行缓慢。
因此,我们存储 tarball,将它们放入队列,然后后台工作程序根据可用性从队列中取出发布任务并处理它们。99% 的发布在提交后 30 毫秒内被后台工作程序取出并处理。然而,如果确实出现大的峰值,我们可以通过稍微减慢处理速度来优雅地处理这些峰值。
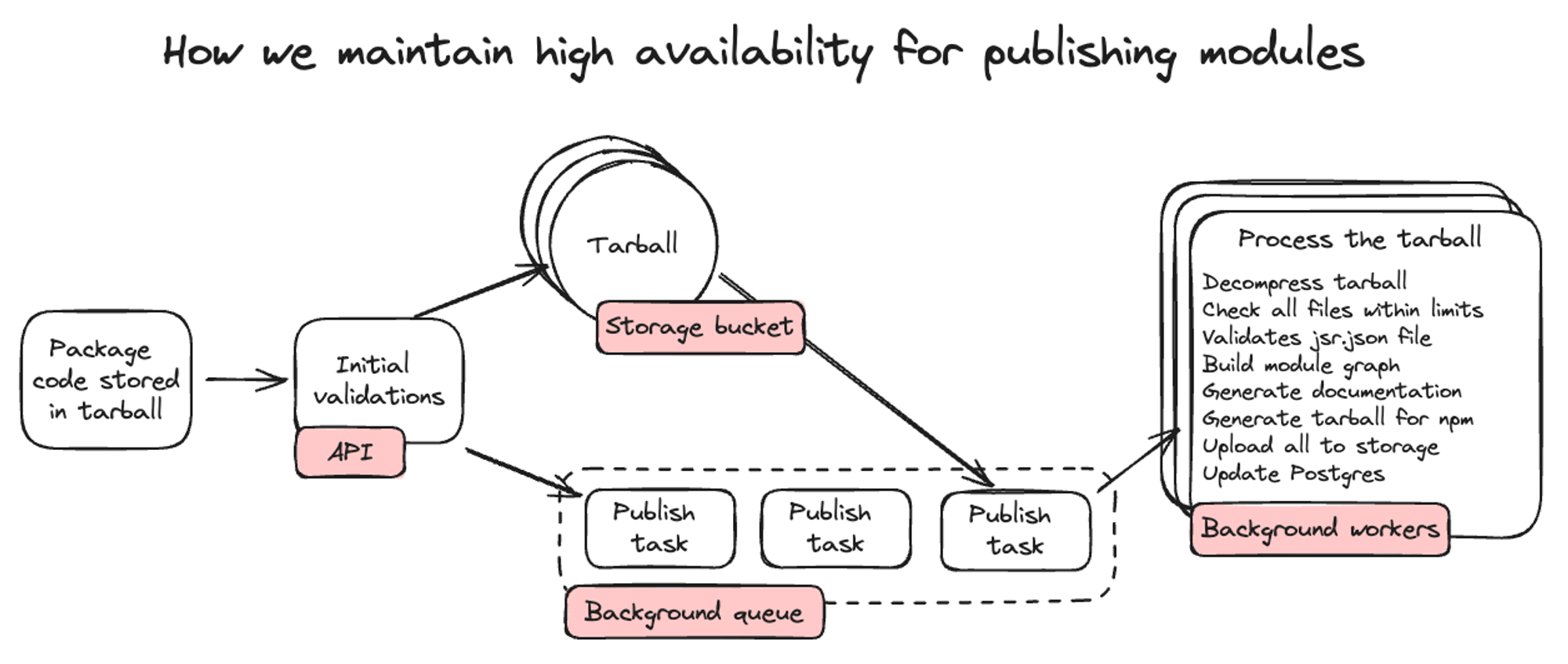
当后台工作程序接收到发布任务时,它首先解压 tarball 并检查其中的所有文件是否在可接受的限制内。然后它验证 jsr.json 文件是否具有有效的 "name"、"version" 和 "exports" 字段。之后,我们构建整个模块的模块图,这有助于验证包代码。模块图映射了包中每个模块之间的关系,检查:
- 您的代码是有效的 JavaScript 或 TypeScript
- 所有导入的模块确实存在
- 所有依赖项都已版本化
对于大多数包来说,所有这些都在几十毫秒内完成。
自动生成文档并上传模块到存储
验证完成后,我们根据此模块图为包生成文档。这完全使用 Rust 中的 TypeScript 语法分析来完成。结果上传到存储桶。我们将在某个时候撰写另一篇博客文章,详细介绍其工作原理,因为它非常有趣!
然后,我们将每个模块单独上传(完全按原样,不进行任何转换)到 modules 存储桶。这个存储桶以后会很重要,请记住它!
将 TypeScript 转换为用于 npm 的 .js 和 .d.ts 文件
接下来,我们为 JSR 的 npm 兼容层生成一个 tarball。为此,我们将您的 TypeScript 源代码转换为 .js 代码文件和 .d.ts 声明文件。这完全是在 Rust 中完成的——据我们所知,这是第一个不使用 Microsoft 用 JavaScript 编写的 TypeScript 编译器来生成 .d.ts 的大规模部署(令人兴奋!)。此 tarball 中的代码已从 JSR 的一致模块格式重写回 node_modules/ 解析能理解的导入,并带有一个 package.json。完成后,这也上传到存储桶。
最后,我们完成了。Postgres 数据库已用新版本更新,jsr publish / deno publish 命令已收到发布完成的通知,并且该包已上线互联网。现在您访问 https://jsr.deno.org.cn,更新的版本将显示在包页面上。
🚨️ 旁注 🚨️
我们对无需使用
tsc即可从.ts源代码生成.d.ts文件的能力 超级 兴奋。这是 TypeScript 正在积极鼓励的事情。例如,Bloomberg 和 Google 与 TypeScript 团队合作,一直在努力为 TypeScript 添加一个isolatedDeclarations选项,这将使在 TSC 之外的声明发出变得轻而易举。我们相信,很快,更多的工具将能够无需使用tsc即可发出.d.ts文件。
以 100% 的可靠性提供模块服务
我已经铺垫够久了——这篇博客文章开头我就告诉过您,我们的模块/npm tarball 服务非常重要,必须超级健壮。那么,秘诀是什么呢?
实际上,没有什么魔法。我们使用了非常平淡、非常成熟、非常可靠的云基础设施。
https://jsr.deno.org.cn 托管在 Google Cloud 上。流量由 Google Cloud L7 负载均衡器通过任播 IP 地址接收。它终止 TLS。然后它查看路径、请求方法和头信息,以确定请求是发送到 API 服务器、前端,还是直接连接到包含源代码和 npm tarball 的 Cloud Storage 存储桶的 Google Cloud CDN 后端。
那么,我们如何使模块服务可靠呢?我们将整个问题都交给了 Google Cloud。与托管 google.com 和 YouTube 的基础设施相同的基础设施被用于托管 JSR 上的模块。我们的自定义代码都没有位于这个热路径中——这很重要,因为这意味着我们不会破坏它。只有当 Google 本身宕机时,JSR 才会宕机。但在那个时候——可能一半的互联网都宕机了,所以您甚至不会注意到😅。
就这样?
对于注册表方面,是的,大部分如此。我省略了我们如何进行文档渲染、如何计算 JSR 评分、计算包依赖项和被依赖项、如何与 GitHub Actions 集成 OIDC、如何与 Sigstore 集成以进行溯源证明……但我们可以下次再谈论这些🙂。
如果您对本文中提到的任何内容感兴趣——从API 服务器,到前端和Google Cloud 的 Terraform 配置,再到deno publish 的实现——您可以自己查看它们,因为 JSR 完全开源,采用 MIT 许可证!
我们欢迎所有贡献者!您可以在 Twitter 上 提出问题、提交 PR 或向我提问。
在 JSR 见!
您喜欢这篇关于 JSR 内部机制的文章吗?
我们将很快发布另一篇文章,详细介绍
deno如何从 JSR 安装包。在 Twitter 上关注我们获取更新:@jsr_io 或 @deno_land。