
您不需要构建步骤

最早火起来的 XKCD 漫画之一是这一幅,#303

如今,网页开发者版则会是“我的网站正在构建中”,而他们则会在 VR 中玩剑。
如今,网站构建耗时较长。一个大型的 Next.js 11 网站需要数分钟才能构建完成。这是开发周期中的时间浪费。像Vite或Turbopack这样的构建工具则强调了它们缩短这一时间的能力。
但更深层的问题尚未被考虑
我们为什么需要构建步骤?
构建如何成为常态
在过去简单的时代,你只需在你的index.html文件中添加几个<script src="my_jquery_script.js"></script>标签,一切就搞定了。
接着 Node 诞生了,它允许开发者使用 JavaScript 编写服务器和后端。很快,开发者不再需要掌握多种语言来构建可扩展的、生产就绪的应用程序。他们只需要了解 JavaScript。
如果我们就此打住,一切都会安好。但在某个时候,有人提出了一个危险的问题
如果我能在浏览器中编写服务器端 JS 呢?
Node 的服务器端 JavaScript 与浏览器 JavaScript 不兼容,因为每种实现都满足两个截然不同的系统
- Node 是围绕文件系统构建的。 服务器具有 HTTP 驱动的 I/O,但其内部核心在于在文件系统中找到正确的文件。
- JavaScript 是为浏览器而创建的,其中脚本/资源通过 URL 异步导入。
推动构建步骤必要性的其他关键问题包括
- 浏览器没有“包管理器”,而 npm 很快成为 Node 和整个 JavaScript 事实上的包管理器。前端开发者希望有一种简单的方法来管理浏览器中的 JavaScript 依赖项。
- npm 模块及其导入方式(CommonJS)在浏览器中不受支持。
- 浏览器 JavaScript 持续发展(自 2009 年以来,它增加了 Promises、
async/await、顶层await、ES 模块和类),而 Node 的 JavaScript 则落后几个周期。 - 服务器上使用了不同风格的 JavaScript。CoffeeScript 为该语言带来了 Python 和 Ruby 风格的语法,JSX 允许编写 HTML 标记,而 TypeScript 则实现了类型安全。但所有这些都需要转换为常规 JavaScript 以供浏览器使用。
- Node 采用模块化设计,因此来自不同 npm 模块的代码需要进行打包和压缩,以减少发送到客户端的代码量。
- 原始代码中使用的一些功能可能在旧版浏览器中不可用,因此需要添加polyfills来弥补这一差距。
- CSS 框架和预处理器(例如LESS和SASS),它们旨在改善编写和维护复杂 CSS 代码库的体验,需要被转译成原生的、浏览器可解析的 CSS。
- 通过 HTML 渲染动态数据(类似于静态网站生成器)通常需要在 HTML 部署到托管服务提供商之前进行单独的步骤。
随着时间的推移,框架和元框架通过简化复杂应用的编写和管理来改善开发者体验。但更好的开发者体验的代价是更复杂的构建步骤。例如,你可以创建一个零构建的博客并用 HTML 编写它。或者,你可以用 markdown 编写你的博客,然后通过 HTML 渲染,这需要一个构建步骤。
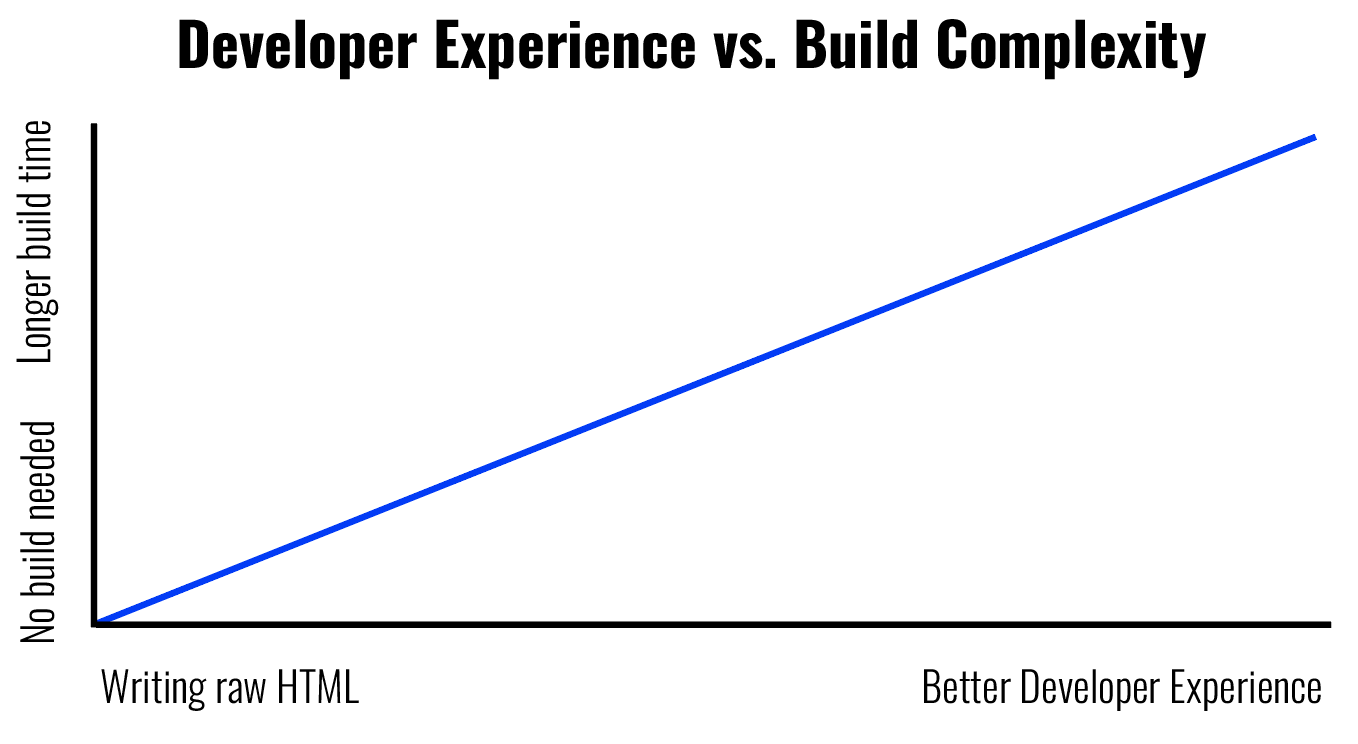
但并非所有构建步骤都是为了提供良好的开发者体验。其他一些是为了提高最终用户的性能(例如,优化步骤,如创建多种图像尺寸并将其转换为最佳格式)。
总而言之,不可避免地,为了使代码在浏览器中运行,必须应用一系列代码转换,这便是我们今天所熟知的…… 构建步骤。
JavaScript 构建工具的兴起
为了满足在浏览器中运行服务器端 JavaScript 的日益增长的需求,多个开源构建工具应运而生,标志着 JavaScript “构建工具生态系统”的到来。
2011 年,Browserify推出,用于为浏览器打包 Node/npm。随后是 Gulp(2013 年)以及其他构建工具、任务运行器等,以管理各种构建任务,使开发者能够继续为浏览器编写 Node 代码。越来越多的构建工具涌现出来。
以下是历年来构建工具的不完全列表
- Browserify - 2011
- Grunt - 2012
- Bower - 2012
- Gulp - 2013
- Babel - 2014
- Webpack - 2014
- Rollup - 2015
- Parcel - 2017
- SWC - 2019
- Vite - 2020
- ESBuild - 2020
- Turbopack - 2022
到 2020 年代,构建工具已成为其独立的 JS 库/框架类别。其中许多工具还拥有自己的插件和加载器生态系统,以允许开发者使用他们喜欢的技术。
例如,Webpack 提供了各种加载器用于 SASS、Babel、SVG 和 Bootstrap 等多种技术。这使得开发者能够选择自己的构建栈:他们可以使用 webpack 作为模块打包器,babel 作为 TS 转译器,并使用 postcss 加载器处理 Tailwind。
在现代 Web 开发中,构建步骤是不可避免的。但在我们问是否需要构建工具之前,让我们先问
究竟需要做些什么才能让服务器端 JavaScript 在浏览器中运行?
Next.js 的四步构建过程
让我们来看一个 Next.js 的实际例子。我们不启动其基本应用,而是使用博客启动器作为你可能使用此框架构建的示例
npx create-next-app --example blog-starter blog-starter-app不做任何改动,我们运行
npm run build这将启动一个四步流程,让你的 Next.js 项目在浏览器中运行
构建过程中的每一步要么是为了支持开发者编写代码的体验,要么是为了提高最终用户的性能。让我们深入了解。
编译
当你构建一个 Web 应用时,你的主要关注点是生产力和体验。因此你会使用像 Next.js 这样的框架,这意味着你也可能在使用 React、ESM 模块、JSX、async/await、TypeScript 等。但这些代码需要转换为原生 JavaScript 以供浏览器使用,这发生在编译步骤中
- 首先,解析代码并将其转换为一种抽象表示,称为抽象语法树
- 然后,将此 AST 转换为目标语言支持的表示形式
- 最后,根据新的 AST 表示形式生成新代码
如果你想了解更多关于编译器内部工作原理的信息,《超级微型编译器》是一篇关于其工作原理的极佳教程。
Next.js 的第一步是将所有代码编译成纯 JavaScript。让我们以[slug].tsx中的 Post 函数为例
export default function Post({ post, morePosts, preview }: Props) {
const router = useRouter()
if (!router.isFallback && !post?.slug) {
return <ErrorPage statusCode={404} />
}
return (
<Layout preview={preview}>
<Container>
<Header />
{router.isFallback ? (
<PostTitle>Loading…</PostTitle>
) : (
<>
<article className="mb-32">
<Head>
<title>
{post.title} | Next.js Blog Example with {CMS_NAME}
</title>
<meta property="og:image" content={post.ogImage.url} />
</Head>
<PostHeader
title={post.title}
coverImage={post.coverImage}
date={post.date}
author={post.author}
/>
<PostBody content={post.content} />
</article>
</>
)}
</Container>
</Layout>
)
}编译器将解析这段代码,将其转换为 AST,然后将该 AST 转换为浏览器 JS 所需的正确函数形式,并生成新代码。以下是该函数编译后发送到浏览器的代码
function y(e) {
let { post: t, morePosts: n, preview: l } = e,
c = (0, r.useRouter)();
return c.isFallback || (null == t ? void 0 : t.slug)
? (0, s.jsx)(v.Z, {
preview: l,
children: (0, s.jsxs)(a.Z, {
children: [
(0, s.jsx)(h, {}),
c.isFallback
? (0, s.jsx)(j, {
children: "Loading…",
})
: (0, s.jsx)(s.Fragment, {
children: (0, s.jsxs)("article", {
className: "mb-32",
children: [
(0, s.jsxs)(N(), {
children: [
(0, s.jsxs)("title", {
children: [
t.title,
" | Next.js Blog Example with ",
w.yf,
],
}),
(0, s.jsx)("meta", {
property: "og:image",
content: t.ogImage.url,
}),
],
}),
(0, s.jsx)(p, {
title: t.title,
coverImage: t.coverImage,
date: t.date,
author: t.author,
}),
(0, s.jsx)(x, {
content: t.content,
}),
],
}),
}),
],
}),
})
: (0, s.jsx)(i(), {
statusCode: 404,
});
}压缩
当然,这段代码并非供人阅读,它只需被浏览器理解即可。压缩步骤用单个字符替换函数和组件名称,以减少发送到浏览器的千字节数,从而提高最终用户的性能。
以上也是“美化”后的版本。以下是它实际的样子
function y(e) {
let { post: t, morePosts: n, preview: l } = e, c = (0, r.useRouter)();
return c.isFallback || (null == t ? void 0 : t.slug)
? (0, s.jsx)(v.Z, {
preview: l,
children: (0, s.jsxs)(a.Z, {
children: [
(0, s.jsx)(h, {}),
c.isFallback
? (0, s.jsx)(j, { children: "Loading…" })
: (0, s.jsx)(s.Fragment, {
children: (0, s.jsxs)("article", {
className: "mb-32",
children: [
(0, s.jsxs)(N(), {
children: [
(0, s.jsxs)("title", {
children: [
t.title,
" | Next.js Blog Example with ",
w.yf,
],
}),
(0, s.jsx)("meta", {
property: "og:image",
content: t.ogImage.url,
}),
],
}),
(0, s.jsx)(p, {
title: t.title,
coverImage: t.coverImage,
date: t.date,
author: t.author,
}),
(0, s.jsx)(x, { content: t.content }),
],
}),
}),
],
}),
})
: (0, s.jsx)(i(), { statusCode: 404 });
}打包
以上所有代码都包含在一个名为(对于本次构建)[slug]-af0d50a2e56018ac.js.的文件中。当该代码经过美化后,文件长度为 447 行。相比之下,我们编辑的原始 [slug].tsx 代码只有 56 行。
为什么我们交付了一个大 10 倍的文件?
因为构建过程的另一个关键部分:打包。
尽管[slug].tsx只有 56 行长,但它依赖于许多其他依赖项和组件,而这些依赖项和组件又依赖于更多的依赖项和组件。所有这些模块都需要加载才能使[slug].tsx正常工作。
让我们使用dependency cruiser来可视化这一点。首先,我们只看组件
npx depcruise --exclude "^node_modules" --output-type dot pages | dot -T svg > dependencygraph.svg这是依赖图
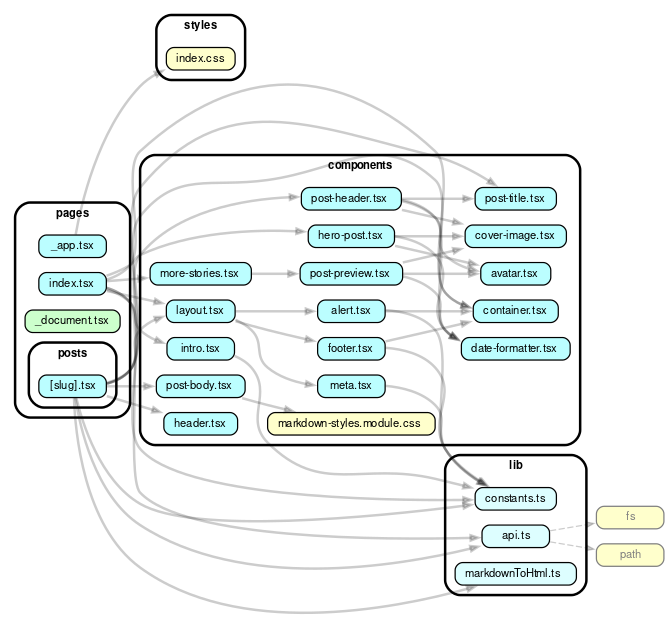
还不错。但这些都存在节点模块依赖项。让我们移除--exclude "^node_modules"来查看此项目中的所有内容
npx depcruise --output-type dot pages | dot -T svg > dependencygraph.svg当我们把这些因素考虑进去时,图表会变得更大。比如,巨大。它太大了,为了让图片更有趣,我们把它标注得像一张有趣的、中世纪的地图。(另外,这是一个 SVG 文件,所以请随意在新标签页中打开它,你可以放大查看所有有趣的细节。)

(谁知道date-fns会涉及这么多呢?)
打包器需要为代码的入口点(通常是 index.js)创建依赖图,然后反向查找index.js所依赖的一切,接着是index.js所依赖的又依赖的一切,依此类推。然后,它将所有这些打包到一个可以发送到浏览器的单个输出文件中。
对于大型项目,大部分构建时间都花在这里:遍历并创建依赖图,然后将所需内容添加到一个单独的包中发送给客户端。
代码分割
或者,如果你使用代码分割,则不然。
如果没有代码分割,当用户首次访问网站时,无论是否需要所有 JavaScript 代码,一个单独的、打包好的 JS 文件都会被发送到客户端。有了代码分割这个性能优化步骤,JavaScript 会根据入口点(例如按页面或 UI 组件)或动态导入进行分块(因此每次只需发送一小部分 JavaScript)。代码分割有助于“按需加载”用户当前需要的内容,只加载必要的部分,并避免加载可能永远不会使用的代码。使用 React,你可以实现高达30% 的主包大小减少。
在我们的例子中,[slug]-af0d50a2e56018ac.js是加载特定博客文章页面所需的代码,它不包含首页或网站上任何其他组件的代码。
你现在可以开始明白为什么生态系统中构建系统和工具如此之多了:这太复杂了。我们甚至还没有深入讨论所有你需要配置和编译 CSS 的选项。YouTube 上的 Webpack 教程简直是几个小时长。漫长的构建时间是常见的挫败感,以至于最近的 Next.js 13 更新的主要主题就是更快的构建。
随着 JavaScript 社区致力于改善应用构建的开发者体验(元框架、CSS 预处理器、JSX 等),它也必须致力于构建更好的工具和任务运行器,以减轻构建步骤的痛苦。
如果还有另一种方法呢?
使用 Deno 和 Fresh 进行非构建
我发现 Deno 也很相似:如果你通过 Deno 学习服务器端 JavaScript,你可能会在过程中偶然学会 Web 平台知识。这是可转移的知识。
—— Jim Nielsen,Deno 具备 Web 特性(第二部分)
上述所有构建步骤都源于一个简单的问题——Node 的 JavaScript 已经与浏览器中的 JavaScript 分道扬镳。但如果我们能从一开始就编写兼容浏览器、使用fetch等 Web API 和原生 ESM 导入的 JavaScript 呢?
这就是 Deno。Deno 采取的方法是,Web JS 近年来已大幅改进,现在是一种极其强大的脚本语言。我们都应该使用它。
以下是如何像上面那样做同样的事情,构建一个博客,但使用 Deno 和Fresh。
Fresh 是一个基于 Deno 构建的 Web 框架,它没有构建步骤——没有打包,没有转译——这是其设计使然。当请求进入服务器时,Fresh 会即时渲染每个页面并仅发送 HTML(除非涉及 Island,届时也会只发送所需数量的 JavaScript)。
即时构建而非打包
不进行打包体现在这第一部分:即时构建。使用 Fresh 渲染页面就像加载一个普通的网页。因为所有导入都是 URL,你加载的页面会调用 URL 来加载它所需的其他代码(可以是源文件,如果之前使用过也可以来自缓存)。
使用 Fresh,当用户点击一个文章页面时,/routes/[slug].tsx会加载。此页面导入这些模块
import { Handlers, PageProps } from "$fresh/server.ts";
import { Head } from "$fresh/runtime.ts";
import { getPost, Post } from "@/utils/posts.ts";
import { CSS, render } from "$gfm";这可能看起来很像在 Node 中导入任何东西。但这仅仅是因为我们使用了来自我们的import map的说明符。当这些导入被解析时,它们是
import { Handlers, PageProps } from "https://deno.land/x/fresh@1.1.0/server.ts";
import { Head } from "https://deno.land/x/fresh@1.1.0/runtime.ts";
import { getPost, Post } from "../utils/posts.ts";
import { CSS, render } from "https://deno.land/x/gfm@0.1.26/mod.ts";我们从我们自己的模块posts.ts中导入getPost和Post。在这些组件中,我们正在从其他 URL 导入模块
import { extract } from "https://deno.land/std@0.160.0/encoding/front_matter.ts";
import { join } from "https://deno.land/std@0.160.0/path/posix.ts";在依赖图中的任何给定点,我们都只是从其他 URL 调用代码。就像乌龟一样,一路下去都是 URL。
即时转译
Fresh 也不需要任何单独的转译步骤,因为所有这些都在请求时即时发生
- 使 TypeScript 和 TSX 在浏览器中工作:Deno 运行时开箱即用,在请求时即时转译 TypeScript 和 TSX。
- 服务器端渲染:通过模板传递动态数据生成 HTML 也在请求时发生。
- 通过 Islands 编写客户端 TypeScript:客户端 TypeScript 会按需转译为 JavaScript,这是必要的,因为浏览器不理解 TypeScript
为了让你的 Fresh 应用性能更高,所有客户端 JavaScript/TypeScript 在首次请求后都会被缓存,以便后续快速检索。
更好的代码,更快的速度
只要开发者不是编写纯粹的 HTML、JS 和 CSS,并且需要为最终用户的性能优化资产,那么某种“构建”步骤就不可避免。这个步骤是耗时数分钟并在 CI/CD 中进行的独立步骤,还是在请求发生时即时进行,取决于你选择的框架或技术栈。
但移除构建步骤意味着你可以更快地行动,并提高生产力。更长时间地保持心流状态。在修改代码时,不再需要剑斗休息(抱歉)或上下文切换。
你也可以更快地部署。由于没有构建步骤,特别是在使用Deno Deploy 的v8 隔离云时,你的部署在全球范围内只需几秒钟,因为它只是上传几 KB 的 JavaScript。
你还在编写更好的代码,并拥有更好的开发者体验。你无需在试图通过打包器网络将 Node、ESM 和浏览器兼容的 JavaScript 联系起来时,学习 Node 或特定供应商的 API,而是可以编写 Web 标准 JavaScript,学习可以与任何云原语重复使用的 API。
跳过构建步骤,尝试使用Fresh和Deno Deploy来做些什么吧。