
使用 Drizzle ORM 和 Deno 构建数据库应用

Drizzle ORM 是一个 TypeScript ORM,它提供了一种类型安全的方式来与数据库交互。在本教程中,我们将使用 Deno 和 PostgreSQL 设置 Drizzle ORM,以创建、读取、更新和删除恐龙数据。
您可以在这个 GitHub 仓库中找到本教程的所有代码。
🚨️ Deno 2 已发布。 🚨️
凭借与 Node/npm 的向后兼容性、内置包管理、一体化零配置工具链,以及原生 TypeScript 和Web API 支持,编写 JavaScript 从未如此简单。
安装 Drizzle
首先,我们将使用 Deno 的 npm 兼容性安装所需的依赖项。我们将使用 Drizzle 和 Postgres,但您也可以使用 MySQL 或 SQLite。(如果您没有 Postgres,可以在此处安装。)
deno install npm:drizzle-orm npm:drizzle-kit npm:pg npm:@types/pg这将安装 Drizzle ORM 及其相关工具 — drizzle-kit 用于模式迁移,pg 用于 PostgreSQL 连接,以及PostgreSQL 的 TypeScript 类型。这些包将允许我们以类型安全的方式与数据库交互,同时保持与 Deno 运行时环境的兼容性。
它还将在您的项目根目录下创建一个 deno.json 文件来管理 npm 依赖项
{
"imports": {
"@types/pg": "npm:@types/pg@^8.11.10",
"drizzle-kit": "npm:drizzle-kit@^0.27.2",
"drizzle-orm": "npm:drizzle-orm@^0.36.0",
"pg": "npm:pg@^8.13.1"
}
}配置 Drizzle
接下来,在您的项目根目录下创建一个 drizzle.config.ts 文件。该文件将配置 Drizzle 以与您的 PostgreSQL 数据库协同工作
import { defineConfig } from "drizzle-kit";
export default defineConfig({
out: "./drizzle",
schema: "./src/db/schema.ts",
dialect: "postgresql",
dbCredentials: {
url: Deno.env.get("DATABASE_URL")!,
},
});这些配置设置确定
- 迁移文件的输出位置 (
./drizzle) - 模式定义的查找位置 (
./src/db/schema.ts) - 将 PostgreSQL 作为您的数据库方言,以及
- 如何使用存储在环境变量中的 URL 连接到数据库
drizzle-kit 将使用此配置来管理您的数据库模式并自动生成 SQL 迁移。
我们还需要在项目根目录下创建一个包含 DATABASE_URL 连接字符串的 .env 文件
DATABASE_URL=postgresql://[user[:password]@][host][:port]/[dbname]请务必将登录凭据替换为您的凭据。
接下来,让我们连接到数据库并使用 Drizzle 填充我们的表。
定义模式
您可以使用 Drizzle 通过两种方式定义表模式。如果您已经定义了 Postgres 表,您可以使用 pull 推断它们;否则,您可以在代码中定义它们,然后使用 Drizzle 创建新表。我们将在下面探讨这两种方法。
使用 pull 推断模式
如果您在添加 Drizzle 之前已经有 Postgres 表,那么您可以使用命令 npm:drizzle-kit pull 内省(反向工程)数据库模式以自动生成 TypeScript 类型和表定义。这在处理现有数据库或希望确保代码与数据库结构保持同步时特别有用。
假设我们当前的数据库已经有以下表模式
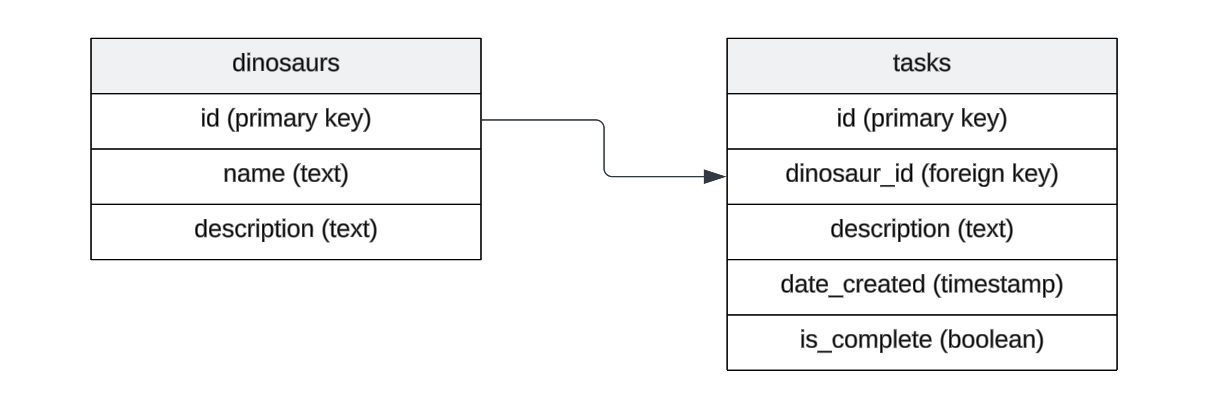
我们将运行以下命令来内省数据库并在 ./drizzle 目录下填充多个文件
deno --env -A --node-modules-dir npm:drizzle-kit pull
Failed to find Response internal state key
No config path provided, using default 'drizzle.config.ts'
Reading config file '/private/tmp/deno-drizzle-example/drizzle.config.ts'
Pulling from ['public'] list of schemas
Using 'pg' driver for database querying
[✓] 2 tables fetched
[✓] 8 columns fetched
[✓] 0 enums fetched
[✓] 0 indexes fetched
[✓] 1 foreign keys fetched
[✓] 0 policies fetched
[✓] 0 check constraints fetched
[✓] 0 views fetched
[i] No SQL generated, you already have migrations in project
[✓] You schema file is ready ➜ drizzle/schema.ts 🚀
[✓] You relations file is ready ➜ drizzle/relations.ts 🚀--env 标志读取包含数据库 URL 的 .env 文件,并使用 --node-modules-dir 标志创建一个 node_modules 文件夹,这将允许我们正确使用 drizzle-kit。上述命令将在 ./drizzle 目录下创建一些文件,这些文件定义了模式、跟踪 更改,并为数据库 迁移提供 必要信息
drizzle/schema.ts:此 文件使用 Drizzle ORM 的模式 定义语法定义数据库 模式。drizzle/relations.ts:此 文件旨在 使用 Drizzle ORM 的关系 API 定义表之间的关系。drizzle/0000_long_veda.sql:一个 SQL 迁移 文件,其中包含 用于创建数据库 表(或多个表)的 SQL 代码。该 代码已被注释掉 — 如果 您想在新 环境中运行此迁移来 创建表(或多个表),可以取消注释此代码。drizzle/meta/0000_snapshot.json:一个快照 文件,它表示 您数据库模式的当前状态。drizzle/meta/_journal.json:此文件 跟踪 已应用于 您数据库的迁移。它帮助 Drizzle ORM 了解 哪些迁移已运行 以及哪些迁移仍 需要应用。
首先在 Drizzle 中定义模式
如果您在 Postgres 中还没有定义现有表(例如,您正在开始一个全新的项目),您可以在代码中定义表和类型,并让 Drizzle 创建它们。
让我们创建一个新目录 ./src/db/,并在其中创建一个 schema.ts 文件,我们将用以下内容填充它
// schema.ts
import {
boolean,
foreignKey,
integer,
pgTable,
serial,
text,
timestamp,
} from "drizzle-orm/pg-core";
export const dinosaurs = pgTable("dinosaurs", {
id: serial().primaryKey().notNull(),
name: text(),
description: text(),
});
export const tasks = pgTable("tasks", {
id: serial().primaryKey().notNull(),
dinosaurId: integer("dinosaur_id"),
description: text(),
dateCreated: timestamp("date_created", { mode: "string" }).defaultNow(),
isComplete: boolean("is_complete"),
}, (table) => {
return {
tasksDinosaurIdFkey: foreignKey({
columns: [table.dinosaurId],
foreignColumns: [dinosaurs.id],
name: "tasks_dinosaur_id_fkey",
}),
};
});dinosaurs 和 tasks 这两个表及其关系。了解更多关于使用 Drizzle 定义模式及其关系的信息。一旦我们定义了 ./src/db/schema.ts,我们就可以通过创建迁移来创建表及其指定的关系
deno -A npm:drizzle-kit generate
Failed to find Response internal state key
No config path provided, using default 'drizzle.config.ts'
Reading config file '/private/tmp/drizzle/drizzle.config.ts'
2 tables
dinosaurs 3 columns 0 indexes 0 fks
tasks 5 columns 0 indexes 1 fks上述命令将创建一个包含迁移脚本和日志的 ./drizzle/ 文件夹。
与数据库交互
现在我们已经设置了 Drizzle ORM,我们可以用它来简化 Postgres 数据库中的数据管理。首先,Drizzle 建议将 schema.ts 和 relations.ts 复制到 ./src/db 目录中,以便在应用程序中使用。
让我们创建一个 ./src/db/db.ts,它导出一些辅助函数,这些函数将使我们更容易与数据库交互
import { drizzle } from "drizzle-orm/node-postgres";
import { dinosaurs as dinosaurSchema, tasks as taskSchema } from "./schema.ts";
import { dinosaursRelations, tasksRelations } from "./relations.ts";
import pg from "pg";
import { integer } from "drizzle-orm/sqlite-core";
import { eq } from "drizzle-orm/expressions";
// Use pg driver.
const { Pool } = pg;
// Instantiate Drizzle client with pg driver and schema.
export const db = drizzle({
client: new Pool({
connectionString: Deno.env.get("DATABASE_URL"),
}),
schema: { dinosaurSchema, taskSchema, dinosaursRelations, tasksRelations },
});
// Insert dinosaur.
export async function insertDinosaur(dinosaurObj: typeof dinosaurSchema) {
return await db.insert(dinosaurSchema).values(dinosaurObj);
}
// Insert task.
export async function insertTask(taskObj: typeof taskSchema) {
return await db.insert(taskSchema).values(taskObj);
}
// Find dinosaur by id.
export async function findDinosaurById(dinosaurId: typeof integer) {
return await db.select().from(dinosaurSchema).where(
eq(dinosaurSchema.id, dinosaurId),
);
}
// Find dinosaur by name.
export async function findDinosaurByName(name: string) {
return await db.select().from(dinosaurSchema).where(
eq(dinosaurSchema.name, name),
);
}
// Find tasks based on dinosaur id.
export async function findDinosaurTasksByDinosaurId(
dinosaurId: typeof integer,
) {
return await db.select().from(taskSchema).where(
eq(taskSchema.dinosaurId, dinosaurId),
);
}
// Update dinosaur.
export async function updateDinosaur(dinosaurObj: typeof dinosaurSchema) {
return await db.update(dinosaurSchema).set(dinosaurObj).where(
eq(dinosaurSchema.id, dinosaurObj.id),
);
}
// Update task.
export async function updateTask(taskObj: typeof taskSchema) {
return await db.update(taskSchema).set(taskObj).where(
eq(taskSchema.id, taskObj.id),
);
}
// Delete dinosaur by id.
export async function deleteDinosaurById(id: typeof integer) {
return await db.delete(dinosaurSchema).where(
eq(dinosaurSchema.id, id),
);
}
// Delete task by id.
export async function deleteTask(id: typeof integer) {
return await db.delete(taskSchema).where(eq(taskSchema.id, id));
}现在我们可以将其中一些辅助函数导入到脚本中,在那里我们可以对数据库执行一些简单的 CRUD 操作。让我们创建一个新文件 ./src/script.ts
import {
deleteDinosaurById,
findDinosaurByName,
insertDinosaur,
insertTask,
updateDinosaur,
} from "./db/db.ts";
// Create a new dinosaur.
await insertDinosaur({
name: "Denosaur",
description: "Dinosaurs should be simple.",
});
// Find that dinosaur by name.
const res = await findDinosaurByName("Denosaur");
// Create a task with that dinosaur by its id.
await insertTask({
dinosaurId: res.id,
description: "Remove unnecessary config.",
isComplete: false,
});
// Update a dinosaur with a new description.
const newDeno = {
id: res.id,
name: "Denosaur",
description: "The simplest dinosaur.",
};
await updateDinosaur(newDeno);
// Delete the dinosaur (and any tasks it has).
await deleteDinosaurById(res.id);我们可以运行它,它将执行数据库上的所有操作
deno -A --env ./src/script.ts接下来做什么?
Drizzle ORM 是一种流行的数据映射工具,可以简化数据模型的管理和维护以及与数据库的交互。希望本教程能让您了解如何在 Deno 项目中使用 Drizzle。
现在您已经对如何在 Deno 中使用 Drizzle ORM 有了基本的了解,您可以:
- 添加更复杂的数据库关系
- 使用 Hono 实现 REST API 来提供您的恐龙数据
- 为您的数据库操作添加验证和错误处理
- 为您的数据库交互编写测试
- 将您的应用程序部署到云端
🦕 使用 Deno 和 Drizzle ORM 编码愉快!此技术栈的类型安全性和简洁性使其成为构建现代 Web 应用程序的绝佳选择。
🚨️ 想了解更多 Deno 吗? 🚨️
查看我们新的Deno 学习教程系列,您将在其中学习:
……以及更多内容,以简短、易懂的视频呈现。新教程每周二和周四发布。